- Sqoop - Home
- Sqoop - Introduction
- Sqoop - Installation
- Sqoop - Import
- Sqoop - Import-All-Tables
- Sqoop - Export
- Sqoop - Sqoop Job
- Sqoop - Codegen
- Sqoop - Eval
- Sqoop - List Databases
- Sqoop - List Tables
Sqoop - Introduction
The traditional application management system, that is, the interaction of applications with relational database using RDBMS, is one of the sources that generate Big Data. Such Big Data, generated by RDBMS, is stored in Relational Database Servers in the relational database structure.
When Big Data storages and analyzers such as MapReduce, Hive, HBase, Cassandra, Pig, etc. of the Hadoop ecosystem came into picture, they required a tool to interact with the relational database servers for importing and exporting the Big Data residing in them. Here, Sqoop occupies a place in the Hadoop ecosystem to provide feasible interaction between relational database server and Hadoops HDFS.
Sqoop − SQL to Hadoop and Hadoop to SQL
Sqoop is a tool designed to transfer data between Hadoop and relational database servers. It is used to import data from relational databases such as MySQL, Oracle to Hadoop HDFS, and export from Hadoop file system to relational databases. It is provided by the Apache Software Foundation.
How Sqoop Works?
The following image describes the workflow of Sqoop.
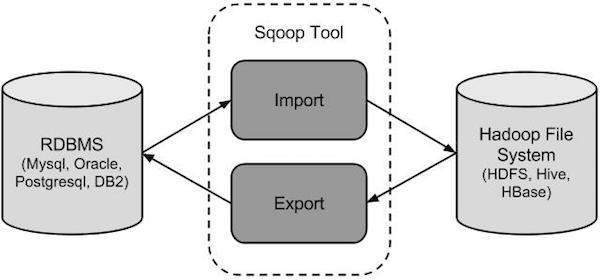
Sqoop Import
The import tool imports individual tables from RDBMS to HDFS. Each row in a table is treated as a record in HDFS. All records are stored as text data in text files or as binary data in Avro and Sequence files.
Sqoop Export
The export tool exports a set of files from HDFS back to an RDBMS. The files given as input to Sqoop contain records, which are called as rows in table. Those are read and parsed into a set of records and delimited with user-specified delimiter.
