- IMS DB - Home
- IMS DB - Overview
- IMS DB - Structure
- IMS DB - DL/I Terminology
- IMS DB - DL/I Processing
- IMS DB - Control Blocks
- IMS DB - Programming
- IMS DB - Cobol Basics
- IMS DB - DL/I Functions
- IMS DB - PCB Mask
- IMS DB - SSA
- IMS DB - Data Retrieval
- IMS DB - Data Manipulation
- IMS DB - Secondary Indexing
- IMS DB - Logical Database
- IMS DB - Recovery
IMS DB - DL/I Processing
IMS DB stores data at different levels. Data is retrieved and inserted by issuing DL/I calls from an application program. We will discuss about DL/I calls in detail in the upcoming chapters. Data can be processed in the following two ways −
- Sequential Processing
- Random Processing
Sequential Processing
When segments are retrieved sequentially from the database, DL/I follows a predefined pattern. Let us understand the sequential processing of IMS DB.

Listed below are the points to note about sequential processing −
Predefined pattern for accessing data in DL/I is first down the hierarchy, then left to right.
The root segment is retrieved first, then DL/I moves to the first left child and it goes down till the lowest level. At the lowest level, it retrieves all the occurrences of twin segments. Then it goes to the right segment.
To understand better, observe the arrows in the above figure that show the flow for accessing the segments. Library is the root segment and the flow starts from there and goes till cars to access a single record. The same process is repeated for all occurrences to get all the data records.
While accessing data, the program usesthe positionin the database which helps to retrieve and insert segments.
Random Processing
Random processing is also known as direct processing of data in IMS DB. Let us take an example to understand random processing in IMS DB −
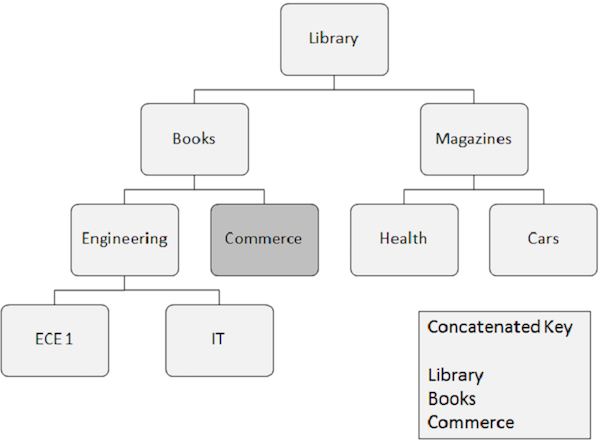
Listed below are the points to note about random processing −
Segment occurrence that needs to be retrieved randomly requires key fields of all the segments it depends upon. These key fields are supplied by the application program.
A concatenated key completely identifies the path from the root segment to the segment which you want to retrieve.
Suppose you want to retrieve an occurrence of the Commerce segment, then you need to supply the concatenated key field values of the segments it depends upon, such as Library, Books, and Commerce.
Random processing is faster than sequential processing. In real-world scenario, the applications combine both sequential and random processing methods together to achieve best results.
Key Field
Points to note −
A key field is also known as a sequence field.
A key field is present within a segment and it is used to retrieve the segment occurrence.
A key field manages the segment occurrence in ascending order.
In each segment, only a single field can be used as a key field or sequence field.
Search Field
As mentioned, only a single field can be used as a key field. If you want to search for the contents of other segment fields which are not key fields, then the field which is used to retrieve the data is known as a search field.