
- Home
- Introduction
- Understanding the Problem
- Identifying the Solution
- Applying Modular Techniques
- Writing the Algorithm
- Flowchart Elements
- Using Clear Instructions
- Correct Programming Techniques
- Debugging
- Program Documentation
- Program Maintenance
Programming Methodologies - Quick Guide
Programming Methodologies - Introduction
When programs are developed to solve real-life problems like inventory management, payroll processing, student admissions, examination result processing, etc. they tend to be huge and complex. The approach to analyzing such complex problems, planning for software development and controlling the development process is called programming methodology.
Types of Programming Methodologies
There are many types of programming methodologies prevalent among software developers −
Procedural Programming
Problem is broken down into procedures, or blocks of code that perform one task each. All procedures taken together form the whole program. It is suitable only for small programs that have low level of complexity.
Example − For a calculator program that does addition, subtraction, multiplication, division, square root and comparison, each of these operations can be developed as separate procedures. In the main program each procedure would be invoked on the basis of users choice.
Object-oriented Programming
Here the solution revolves around entities or objects that are part of problem. The solution deals with how to store data related to the entities, how the entities behave and how they interact with each other to give a cohesive solution.
Example − If we have to develop a payroll management system, we will have entities like employees, salary structure, leave rules, etc. around which the solution must be built.
Functional Programming
Here the problem, or the desired solution, is broken down into functional units. Each unit performs its own task and is self-sufficient. These units are then stitched together to form the complete solution.
Example − A payroll processing can have functional units like employee data maintenance, basic salary calculation, gross salary calculation, leave processing, loan repayment processing, etc.
Logical Programming
Here the problem is broken down into logical units rather than functional units. Example: In a school management system, users have very defined roles like class teacher, subject teacher, lab assistant, coordinator, academic in-charge, etc. So the software can be divided into units depending on user roles. Each user can have different interface, permissions, etc.
Software developers may choose one or a combination of more than one of these methodologies to develop a software. Note that in each of the methodologies discussed, problem has to be broken down into smaller units. To do this, developers use any of the following two approaches −
- Top-down approach
- Bottom-up approach
Top-down or Modular Approach
The problem is broken down into smaller units, which may be further broken down into even smaller units. Each unit is called a module. Each module is a self-sufficient unit that has everything necessary to perform its task.
The following illustration shows an example of how you can follow modular approach to create different modules while developing a payroll processing program.
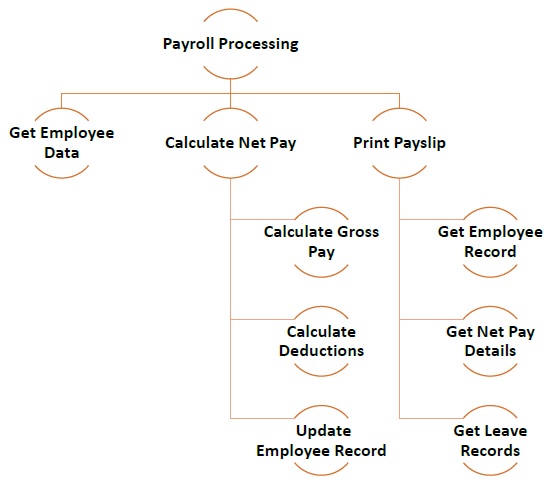
Bottom-up Approach
In bottom-up approach, system design starts with the lowest level of components, which are then interconnected to get higher level components. This process continues till a hierarchy of all system components is generated. However, in real-life scenario it is very difficult to know all lowest level components at the outset. So bottoms up approach is used only for very simple problems.
Let us look at the components of a calculator program.
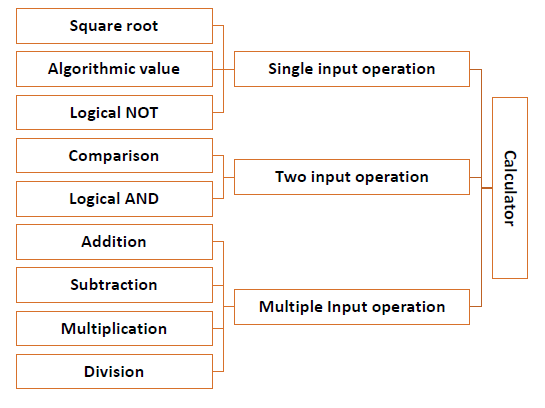
Understanding the Problem
A typical software development process follows these steps −
- Requirement gathering
- Problem definition
- System design
- Implementation
- Testing
- Documentation
- Training and support
- Maintenance
The first two steps assist the team in understanding the problem, the most crucial first step towards getting a solution. Person responsible for gathering requirement, defining the problem and designing the system is called system analyst.
Requirement Gathering
Usually, clients or users are not able to clearly define their problems or requirements. They have a vague idea of what they want. So system developers need to gather client requirements to understand the problem that needs to be resolved, or what needs to be delivered. Detailed understanding of the problem is possible only by first understanding the business area for which the solution is being developed. Some key questions that help in understanding a business include −
- What is being done?
- How is it being done?
- What is the frequency of a task?
- What is the volume of decisions or transactions?
- What are the problems being encountered?
Some techniques that help in gathering this information are −
- Interviews
- Questionnaires
- Studying existing system documents
- Analyzing business data
System analysts needs to create clear and concise but thorough requirements document in order to identify SMART specific, measurable, agreed upon, realistic and time-based requirements. A failure to do so results in −
- Incomplete problem definition
- Incorrect program goals
- Re-work to deliver required outcome to client
- Increased costs
- Delayed delivery
Due to the depth of information required, requirement gathering is also known as detailed investigation.
Problem Definition
After gathering requirements and analyzing them, problem statement must be stated clearly. Problem definition should unambiguously state what problem or problems need to be solved. Having a clear problem statement is necessary to −
- Define project scope
- Keep the team focused
- Keep the project on track
- Validate that desired outcome was achieved at the end of project
Identifying the Solution
Often, coding is supposed to be the most essential part of any software development process. However, coding is just a part of the process and may actually take the minimum amount of time if the system is designed correctly. Before the system can be designed, a solution must be identified for the problem at hand.
The first thing to be noted about designing a system is that initially the system analyst may come up with more than one solutions. But the final solution or the product can be only one. In-depth analysis of data gathered during the requirement gathering phase can help in coming to a unique solution. Correctly defining the problem is also crucial for getting to the solution.
When faced with the problem of multiple solutions, analysts go for visual aids like flowcharts, data flow diagrams, entity relationship diagrams, etc. to understand each solution in depth.
Flowcharting
Flowcharting is the process of illustrating workflows and data flows in a system through symbols and diagrams. It is an important tool to assist the system analyst in identifying a solution to the problem. It depicts the components of the system visually.
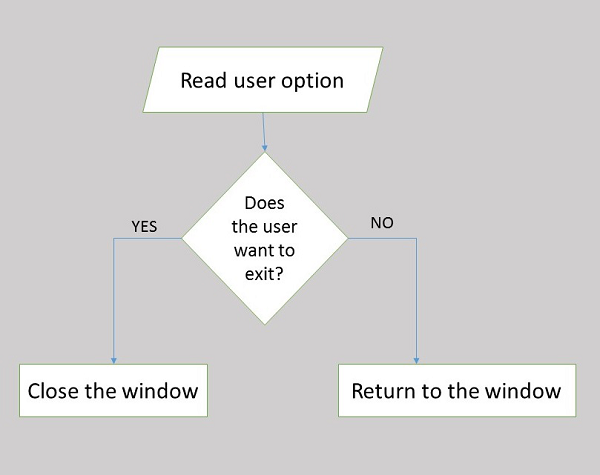
These are the advantages of flowcharting −
Visual representation helps in understanding program logic
They act as blueprints for actual program coding
Flowcharts are important for program documentation
Flowcharts are an important aid during program maintenance
These are the disadvantages of flowcharting −
Complex logic cannot be depicted using flowcharts
In case of any change in logic or data/work flow, flowchart has to be redrawn completely
Data Flow Diagram
Data flow diagram or DFD is a graphical representation of data flow through a system or sub-system. Each process has its own data flow and there are levels of data flow diagrams. Level 0 shows the input and output data for the whole system. Then the system is broken down into modules and level 1 DFD shows data flow for each module separately. Modules may further be broken down into sub-modules if required and level 2 DFD drawn.
Pseudocode
After the system is designed, it is handed over to the project manager for implementation, i.e. coding. The actual coding of a program is done in a programming language, which can be understood only by programmers who are trained in that language. However, before the actual coding occurs, the basic operating principles, work flows and data flows of the program are written using a notation similar to the programming language to be used. Such a notation is called pseudocode.
Here is an example of a pseudocode in C++. The programmer just needs to translate each statement into C++ syntax to get the program code.

Identifying Mathematical Operations
All instructions to the computer are finally implemented as arithmetic and logical operations at machine level. These operations are important because they −
- Occupy memory space
- Take time in execution
- Determine software efficiency
- Affect overall software performance
System analysts try to identify all major mathematical operations while identifying the unique solution to problem at hand.
Applying Modular Techniques
A real-life problem is complex and big. If a monolithic solution is developed it poses these problems −
Difficult to write, test and implement one big program
Modifications after the final product is delivered is close to impossible
Maintenance of program very difficult
One error can bring the whole system to a halt
To overcome these problems, the solution should be divided into smaller parts called modules. The technique of breaking down one big solution into smaller modules for ease of development, implementation, modification and maintenance is called modular technique of programming or software development.
Advantages of Modular Programming
Modular programming offers these advantages −
Enables faster development as each module can be developed in parallel
Modules can be re-used
As each module is to be tested independently, testing is faster and more robust
Debugging and maintenance of the whole program easier
Modules are smaller and have lower level of complexity so they are easy to understand
Identifying the Modules
Identifying modules in a software is a mind boggling task because there cannot be one correct way of doing so. Here are some pointers to identifying modules −
If data is the most important element of the system, create modules that handle related data.
If service provided by the system is diverse, break down the system into functional modules.
If all else fails, break down the system into logical modules as per your understanding of the system during requirement gathering phase.
For coding, each module has to be again broken down into smaller modules for ease of programming. This can again be done using the three tips shared above, combined with specific programming rules. For example, for an object oriented programming language like C++ and Java, each class with its data and methods could form a single module.
Step-by-Step Solution
To implement the modules, process flow of each module must be described in step by step fashion. The step by step solution can be developed using algorithms or pseudocodes. Providing step by step solution offers these advantages −
Anyone reading the solution can understand both problem and solution.
It is equally understandable by programmers and non-programmers.
During coding each statement simply needs to be converted to a program statement.
It can be part of documentation and assist in program maintenance.
Micro-level details like identifier names, operations required, etc. get worked out automatically
Lets look at an example.

Control Structures
As you can see in the above example, it is not necessary that a program logic runs sequentially. In programming language, control structures take decisions about program flow based on given parameters. They are very important elements of any software and must be identified before any coding begins.
Algorithms and pseudocodes help analysts and programmers in identifying where control structures are required.
Control structures are of these three types −
Decision Control Structures
Decision control structures are used when the next step to be executed depends upon a criteria. This criteria is usually one or more Boolean expressions that must be evaluated. A Boolean expression always evaluates to true or false. One set of statements is executed if the criteria is true and another set executed if the criteria evaluates to false. For example, if statement
Selection Control Structures
Selection control structures are used when program sequence depends upon the answer to a specific question. For example, a program has many options for the user. The statement to be executed next will depend on the option chosen. For example, switch statement, case statement.
Repetition / Loop Control Structures
Repetition control structure is used when a set of statements in to be repeated many times. The number of repetitions might be known before it starts or may depend on the value of an expression. For example, for statement, while statement, do while statement, etc.
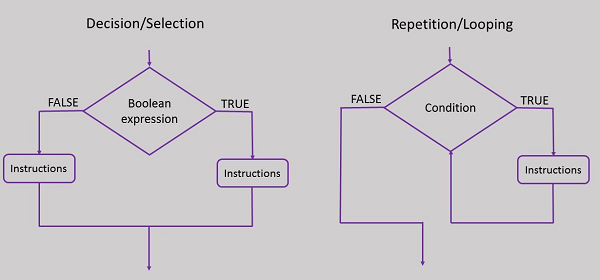
As you can see in the image above, both selection and decision structures are implemented similarly in a flowchart. Selection control is nothing but a series of decision statements taken sequentially.
Here are some examples from programs to show how these statements work −

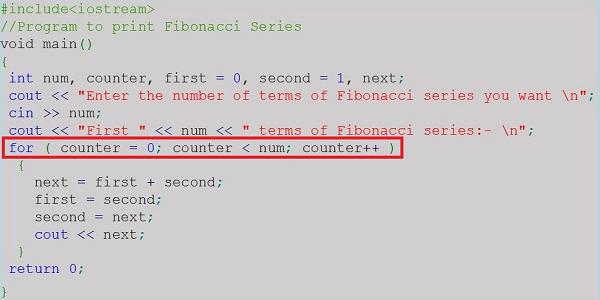
Writing the Algorithm
A finite set of steps that must be followed to solve any problem is called an algorithm. Algorithm is generally developed before the actual coding is done. It is written using English like language so that it is easily understandable even by non-programmers.
Sometimes algorithms are written using pseudocodes, i.e. a language similar to the programming language to be used. Writing algorithm for solving a problem offers these advantages −
Promotes effective communication between team members
Enables analysis of problem at hand
Acts as blueprint for coding
Assists in debugging
Becomes part of software documentation for future reference during maintenance phase
These are the characteristics of a good and correct algorithm −
Has a set of inputs
Steps are uniquely defined
Has finite number of steps
Produces desired output
Example Algorithms
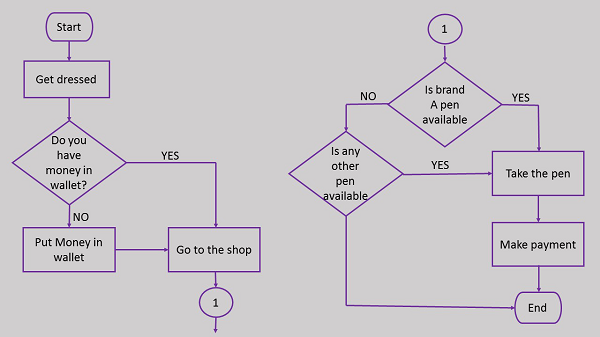
Let us first take an example of a real-life situation for creating algorithm. Here is the algorithm for going to the market to purchase a pen.

Step 4 in this algorithm is in itself a complete task and separate algorithm can be written for it. Let us now create an algorithm to check whether a number is positive or negative.

Flowchart Elements
Flowchart is a diagrammatic representation of sequence of logical steps of a program. Flowcharts use simple geometric shapes to depict processes and arrows to show relationships and process/data flow.
Flowchart Symbols
Here is a chart for some of the common symbols used in drawing flowcharts.
| Symbol | Symbol Name | Purpose |
|---|---|---|
 |
Start/Stop | Used at the beginning and end of the algorithm to show start and end of the program. |
 |
Process | Indicates processes like mathematical operations. |
 |
Input/ Output | Used for denoting program inputs and outputs. |
 |
Decision | Stands for decision statements in a program, where answer is usually Yes or No. |
| Arrow | Shows relationships between different shapes. | |
 |
On-page Connector | Connects two or more parts of a flowchart, which are on the same page. |
 |
Off-page Connector | Connects two parts of a flowchart which are spread over different pages. |
Guidelines for Developing Flowcharts
These are some points to keep in mind while developing a flowchart −
Flowchart can have only one start and one stop symbol
On-page connectors are referenced using numbers
Off-page connectors are referenced using alphabets
General flow of processes is top to bottom or left to right
Arrows should not cross each other
Example Flowcharts
Here is the flowchart for going to the market to purchase a pen.
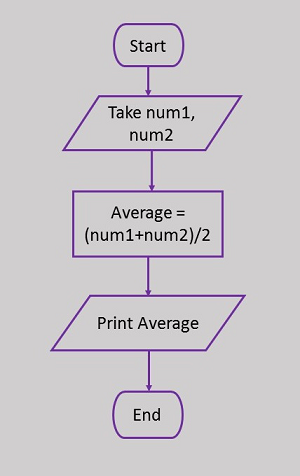
Here is a flowchart to calculate the average of two numbers.
Using Clear Instructions
As you know, computer does not have intelligence of its own; it simply follows the instructions given by the user. Instructions are the building blocks of a computer program, and hence a software. Giving clear instructions is crucial to building a successful program. As a programmer or software developer, you should get into the habit of writing clear instructions. Here are two ways to do that.
Clarity of Expressions
Expression in a program is a sequence of operators and operands to do an arithmetic or logical computation. Here are some examples of valid expressions −
- Comparing two values
- Defining a variable, object or class
- Arithmetic calculations using one or more variables
- Retrieving data from database
- Updating values in database
Writing unambiguous expressions is a skill that must be developed by every programmer. Here are some points to be kept in mind while writing such expressions −
Unambiguous Result
Evaluation of the expression must give one clear cut result. For example, unary operators should be used with caution.
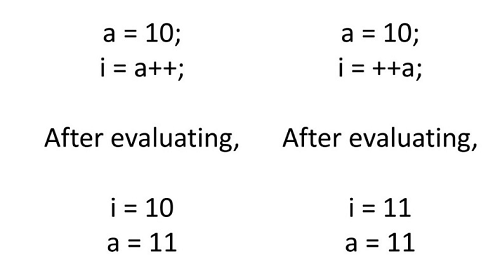
Avoid Complex Expressions
Do not try to achieve many things in a single expression. Break into two or more expressions the moment things start getting complicated.
Simplicity of Instructions
Its not just for computers that you need to write clear instructions. Any one reading the program later (even you yourself!!) should be able to understand what the instruction is trying to achieve. It is very common for programmers not to get a hang of their own programs when they revisit it after some time has passed. This indicates that maintenance and modification of such programs would be quite difficult.
Writing simple instructions helps in avoiding this problem. Here are some tips to write simple instructions −
Avoid clever instructions − Clever instructions might not look that clever later if no one is able to understand it properly.
One instruction per task − Trying to do more than one thing at a time complicates instructions.
Use standards − Every language has its standards, follow them. Remember you are not working alone on the project; follow project standards and guidelines for coding.
Correct Programming Techniques
In this chapter, we will cover how to write a good program. But before we do that, let us see what the characteristics of a good program are −
Portable − The program or software should run on all computers of same type. By same type we mean a software developed for personal computers should run on all PCs. Or a software for written for tablets should run on all tablets having the right specifications.
Efficient − A software that does the assigned tasks quickly is said to be efficient. Code optimization and memory optimization are some of the ways of raising program efficiency.

Effective − The software should assist in solving the problem at hand. A software that does that is said to be effective.
Reliable − The program should give the same output every time the same set of inputs is given.
User friendly − Program interface, clickable links and icons, etc. should be user friendly.
Self-documenting − Any program or software whose identifier names, module names, etc. can describe itself due to use of explicit names.
Here are some ways in which good programs can be written.
Proper Identifier Names
A name that identifies any variable, object, function, class or method is called an identifier. Giving proper identifier names makes a program self-documenting. This means that name of the object will tell what it does or what information it stores. Lets take an example of this SQL instruction:
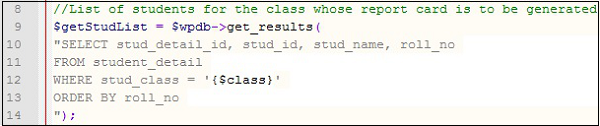
Look at line 10. It tells anyone reading the program that a students ID, name and roll number are to be selected. The names of the variables make this self-explanatory. These are some tips to create proper identifier names −
Use language guidelines
Dont shy from giving long names to maintain clarity
Use uppercase and lowercase letters
Dont give same name to two identifiers even if the language allows it
Dont give same names to more than one identifier even if they have mutually exclusive scope
Comments
In the image above, look at line 8. It tells the reader that the next few lines of code will retrieve list of students whose report card is to be generated. This line is not part of the code but given only to make the program more user friendly.
Such an expression that is not compiled but written as a note or explanation for the programmer is called a comment. Look at the comments in the following program segment. Comments start with //.

Comments can be inserted as −
Prologue to the program to explain its objective
At the beginning and/or end of logical or functional blocks
Make note about special scenarios or exceptions
You should avoid adding superfluous comments as that may prove counterproductive by breaking the flow of code while reading. Compiler may ignore comments and indentations but the reader tends to read each one of them.
Indentation
Distance of text from left or right margin is called indent. In programs, indentation is used to separate logically separated blocks of code. Heres an example of indented program segment:
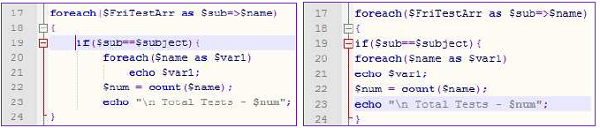
As you can see, indented program is more understandable. Flow of control from for loop to if and back to for is very clear. Indentation is especially useful in case of control structures.
Inserting blank spaces or lines is also part of indentation. Here are some situations where you can and should use indentation −
Blank lines between logical or functional blocks of code within the program
Blank spaces around operators
Tabs at the beginning of new control structures
Programming Methodologies - Debugging
Identifying and removing errors from a program or software is called debugging. Debugging is ideally part of testing process but in reality it is done at every step of programming. Coders should debug the smallest of their modules before moving on. This decreases the number of errors thrown up during the testing phase and reduces testing time and effort significantly. Let us look at the types of errors that can crop up in a program.
Syntax Errors
Syntax errors are the grammatical errors in a program. Every language has its own set of rules, like creating identifiers, writing expressions, etc. for writing programs. When these rules are violated, the errors are called syntax errors. Many modern integrated development environments can identify the syntax errors as you type your program. Else, it will be shown when you compile the program. Let us take an example −
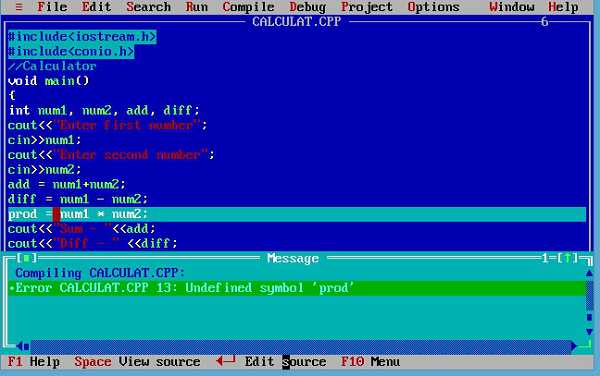
In this program, the variable prod has not been declared, which is thrown up by the compiler.
Semantic Errors
Semantic errors are also called logical errors. The statement has no syntax errors, so it will compile and run correctly. However, it will not give the desired output as the logic is not correct. Let us take an example.
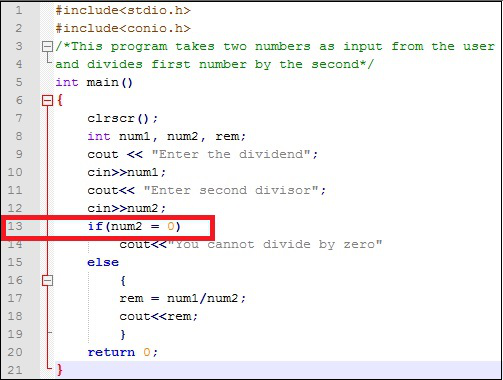
Look at line 13. Here programmer wants to check if the divisor is 0, to avoid division by 0. However, instead of using the comparing operator ==, assignment operator = has been used. Now every time the if expression will evaluate to true and program will give output as You cannot divide by 0. Definitely not what was intended!!
Logical errors cannot be detected by any program; they have to be identified by the programmer herself when the desired output is not achieved.
Runtime Errors
Runtime errors are errors that occur while executing the program. This implies that the program has no syntax errors. Some of the most common run time errors your program may encounter are −
- Infinite loop
- Division by '0'
- Wrong value entered by user (say, string instead of integer)
Code Optimization
Any method by which code is modified to improve its quality and efficiency is called code optimization. Code quality determines life span of code. If the code can be used and maintained for a long period of time, carried over from product to product, its quality is deemed to be high and it has a longer life. On the contrary, if a piece of code can be used and maintained only for short durations, say till a version is valid, it is deemed to be of low quality and has a short life.
Reliability and speed of a code determines code efficiency. Code efficiency is an important factor in ensuring high performance of a software.
There are two approaches to code optimization −
Intuition based optimization (IBO) − Here the programmer tries to optimize the program based on her own skill and experience. This might work for small programs but fails miserably as complexity of the program grows.
Evidence based optimization (EBO) − Here automated tools are used to find out performance bottlenecks and then relevant portions optimize accordingly. Every programming language has its own set of code optimization tools. For example, PMD, FindBug and Clover are used to optimize Java code.
Code is optimized for execution time and memory consumption because time is scarce and memory expensive. There has to be a balance between the two. If time optimization increases load on memory or memory optimization makes the code slower, purpose of optimization will be lost.

Execution Time Optimization
Optimizing code for execution time is necessary to provide fast service to the users. Here are some tips for execution time optimization −
Use commands that have built-in execution time optimization
Use switch instead of if condition
Minimize function calls within loop structures
Optimize the data structures used in the program
Memory Optimization
As you know, data and instructions consume memory. When we say data, it also refers to interim data that is the result of expressions. We also need to keep a track of how many instructions are making up the program or the module we are trying to optimize. Here are some tips for memory optimization −
Use commands that have built-in memory optimization
Keep the use of variables that need to be stored in registers minimum
Avoid declaring global variables inside loops that are executed many times
Avoid using CPU intensive functions like sqrt()
Program Documentation
Any written text, illustrations or video that describe a software or program to its users is called program or software document. User can be anyone from a programmer, system analyst and administrator to end user. At various stages of development multiple documents may be created for different users. In fact, software documentation is a critical process in the overall software development process.
In modular programming documentation becomes even more important because different modules of the software are developed by different teams. If anyone other than the development team wants to or needs to understand a module, good and detailed documentation will make the task easier.
These are some guidelines for creating the documents −
Documentation should be from the point of view of the reader
Document should be unambiguous
There should be no repetition
Industry standards should be used
Documents should always be updated
Any outdated document should be phased out after due recording of the phase out
Advantages of Documentation
These are some of the advantages of providing program documentation −
Keeps track of all parts of a software or program
Maintenance is easier
Programmers other than the developer can understand all aspects of software
Improves overall quality of the software
Assists in user training
Ensures knowledge de-centralization, cutting costs and effort if people leave the system abruptly
Example Documents
A software can have many types of documents associated with it. Some of the important ones include −
User manual − It describes instructions and procedures for end users to use the different features of the software.
Operational manual − It lists and describes all the operations being carried out and their inter-dependencies.
Design Document − It gives an overview of the software and describes design elements in detail. It documents details like data flow diagrams, entity relationship diagrams, etc.
Requirements Document − It has a list of all the requirements of the system as well as an analysis of viability of the requirements. It can have user cases, reallife scenarios, etc.
Technical Documentation − It is a documentation of actual programming components like algorithms, flowcharts, program codes, functional modules, etc.
Testing Document − It records test plan, test cases, validation plan, verification plan, test results, etc. Testing is one phase of software development that needs intensive documentation.
List of Known Bugs − Every software has bugs or errors that cannot be removed because either they were discovered very late or are harmless or will take more effort and time than necessary to rectify. These bugs are listed with program documentation so that they may be removed at a later date. Also they help the users, implementers and maintenance people if the bug is activated.
Program Maintenance
Program maintenance is the process of modifying a software or program after delivery to achieve any of these outcomes −
- Correct errors
- Improve performance
- Add functionalities
- Remove obsolete portions
Despite the common perception that maintenance is required to fix errors that come up after the software goes live, in reality most of the maintenance work involves adding minor or major capabilities to existing modules. For example, some new data is added to a report, a new field added to entry forms, code to be modified to incorporate changed government laws, etc.
Types of Maintenance
Maintenance activities can be categorized under four headings −
Corrective maintenance − Here errors that come up after on-site implementation are fixed. The errors may be pointed out by the users themselves.
Preventive maintenance − Modifications done to avoid errors in future are called preventive maintenance.
Adaptive maintenance − Changes in the working environment sometimes require modifications in the software. This is called adaptive maintenance. For example, if government education policy changes, corresponding changes have to be made in student result processing module of school management software.
Perfective maintenance − Changes done in the existing software to incorporate new requirements from the client is called perfective maintenance. Aim here is to be always be up-to-date with the latest technology.
Maintenance Tools
Software developers and programmers use many tools to assist them in software maintenance. Here are some of the most widely used −
Program slicer − selects a part of the program that would be affected by the change
Data flow analyzer − tracks all possible flows of data in the software
Dynamic analyzer − traces program execution path
Static analyzer − allows general viewing and summarizing of the program
Dependency analyzer − assists in understanding and analyzing interdependence of different parts of the program
