- Home
- Introduction
- Case Study
- Setting up a Project
- Getting Data
- Restructuring Data
- Preparing Data
- Splitting Data
- Building Classifier
- Testing
- Limitations
- Summary
Logistic Regression in Python - Resources
Logistic Regression in Python - Getting Data
The steps involved in getting data for performing logistic regression in Python are discussed in detail in this chapter.
Downloading Dataset
If you have not already downloaded the UCI dataset mentioned earlier, download it now from https://archive.ics.uci.edu/ml/datasets/bank+marketing. Click on the Download Button to download bank+marketing.zip file.

Open the bank+marketing.zip file which contains bank.zip file. The bank.zip file contains the following files −

We will use the bank.csv file for our model development. The bank-names.txt file contains the description of the database that you are going to need later. The bank-full.csv contains a much larger dataset that you may use for more advanced developments.
Here we have included the bank.csv file in the downloadable source zip. This file contains the comma-delimited fields. We have also made a few modifications in the file. It is recommended that you use the file included in the project source zip for your learning.
Loading Data
To load the data from the csv file that you copied just now, type the following statement and run the code.
df = pd.read_csv('bank.csv', header=0, sep=";")
You will also be able to examine the loaded data by running the following code statement −
df.head()
Once the command is run, you will see the following output −
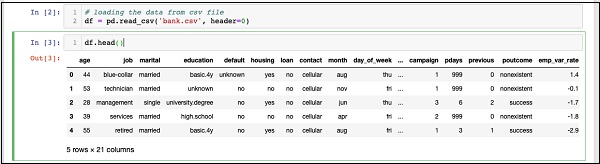
Basically, it has printed the first five rows of the loaded data. Examine the 21 columns present. We will be using only few columns from these for our model development.
Next, we need to clean the data. The data may contain some rows with NaN. To eliminate such rows, use the following command −
df = df.dropna()
Fortunately, the bank.csv does not contain any rows with NaN, so this step is not truly required in our case. However, in general it is difficult to discover such rows in a huge database. So it is always safer to run the above statement to clean the data.
Note − You can easily examine the data size at any point of time by using the following statement −
print (df.shape) (4521, 17)
The number of rows and columns would be printed in the output as shown in the second line above.
Next thing to do is to examine the suitability of each column for the model that we are trying to build.
