- Example - Home
- Example - Environment
- Example - Strings
- Example - Arrays
- Example - Date & Time
- Example - Methods
- Example - Files
- Example - Directories
- Example - Exceptions
- Example - Data Structure
- Example - Collections
- Example - Networking
- Example - Threading
- Example - Applets
- Example - Simple GUI
- Example - JDBC
- Example - Regular Exp
- Example - Apache PDF Box
- Example - Apache POI PPT
- Example - Apache POI Excel
- Example - Apache POI Word
- Example - OpenCV
- Example - Apache Tika
- Example - iText
- Java Useful Resources
- Java - Quick Guide
- Java - Useful Resources
Selected Reading
How to extract content from an ODF using Java
Problem Description
How to extract content from an ODF using java.
Solution
Following is the program to extract content from an ODF using java.
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.odf.OpenDocumentParser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class ExtractContentFromODF {
public static void main(String[] args) throws Exception {
//detecting the file type
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(new File(
"C:/tika/odfExample.odt"));
ParseContext pcontext = new ParseContext();
//Open Document Parser
OpenDocumentParser openofficeparser = new OpenDocumentParser ();
openofficeparser.parse(inputstream, handler, metadata,pcontext);
System.out.println("Contents of the document:" + handler.toString());
System.out.println("Metadata of the document:");
String[] metadataNames = metadata.names();
for(String name : metadataNames) {
System.out.println(name + " : " + metadata.get(name));
}
}
}
Input
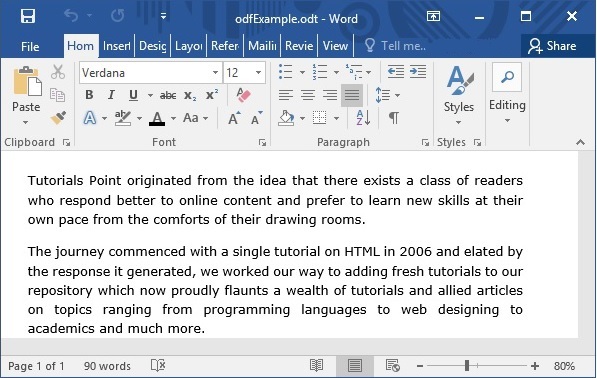
Output
Contents of the document: Tutorials Point originated from the idea that there exists a class of readers who respond better to online content and prefer to learn new skills at their own pace from the comforts of their drawing rooms. The journey commenced with a single tutorial on HTML in 2006 and elated by the response it generated, we worked our way to adding fresh tutorials to our repository which now proudly flaunts a wealth of tutorials and allied articles on topics ranging from programming languages to web designing to academics and much more. Metadata of the document: date : 2017-05-19T09:03:00Z meta:paragraph-count : 1 meta:word-count : 78 meta:initial-author : krishnakasyap Bhagavatula initial-creator : krishnakasyap Bhagavatula dc:creator : krishnakasyap Bhagavatula generator : MicrosoftOffice/15.0 MicrosoftWord Word-Count : 78 dcterms:created : 2017-05-19T09:03:00Z dcterms:modified : 2017-05-19T09:03:00Z Last-Modified : 2017-05-19T09:03:00Z nbPara : 1 Last-Save-Date : 2017-05-19T09:03:00Z meta:character-count : 528 Paragraph-Count : 1 meta:save-date : 2017-05-19T09:03:00Z modified : 2017-05-19T09:03:00Z Edit-Time : PT0S nbCharacter : 528 nbPage : 1 nbWord : 78 Content-Type : application/vnd.oasis.opendocument.text creator : krishnakasyap Bhagavatula meta:author : krishnakasyap Bhagavatula meta:creation-date : 2017-05-19T09:03:00Z Creation-Date : 2017-05-19T09:03:00Z xmpTPg:NPages : 1 Character Count : 528 editing-cycles : 2 Page-Count : 1 Author : krishnakasyap Bhagavatula meta:page-count : 1
java_apache_tika

Advertisements