- JPA - Inicio
- JPA - Introducción
- JPA - Arquitectura
- JPA - Componentes ORM
- JPA - Instalación
- JPA - Administradores de la Entidad
- JPA - JPQL
- JPA - Asignaciones de Avanzada
- JPA - Relaciones de la Entidad
- JPA - API Criterios
JPA - Componentes ORM
La mayora de las aplicaciones que utilizan bases de datos relacionales para almacenar datos. Recientemente, muchos proveedores de base de datos de objeto de reducir su carga de mantenimiento de datos. Esto significa Object Relational Mapping de base de datos o las tecnologas estn al cuidado de almacenar, recuperar, actualizar y mantener los datos. La parte principal de este objeto es tecnologa relacional orm mapeo.xml files. Como xml no necesitan compilacin, podemos realizar cambios fcilmente a varias fuentes de datos con menos administracin.
Object Relational Mapping
Object Relational Mapping (ORM) informa brevemente sobre lo que es ORM y cmo funciona. ORM es una capacidad de programacin para convertir los datos de tipo de objeto de tipo relacional y viceversa.
La principal caracterstica de ORM es de cartografa o enlazar un objeto a sus datos en la base de datos. Si bien la cartografa, tenemos que tener en cuenta los datos, el tipo de datos, y sus relaciones con la entidad o entidades en cualquier otra tabla.
Funciones avanzadas
Persistencia idiomticas: le permite escribir la persistencia clases utilizando las clases orientadas a objetos.
Alto rendimiento : tiene muchos buscar tcnicas tcnicas de bloqueo y esperanzador.
Fiable: es muy estable y utilizado por muchos programadores profesionales.
Arquitectura ORM
El ORM arquitectura es similar al siguiente.
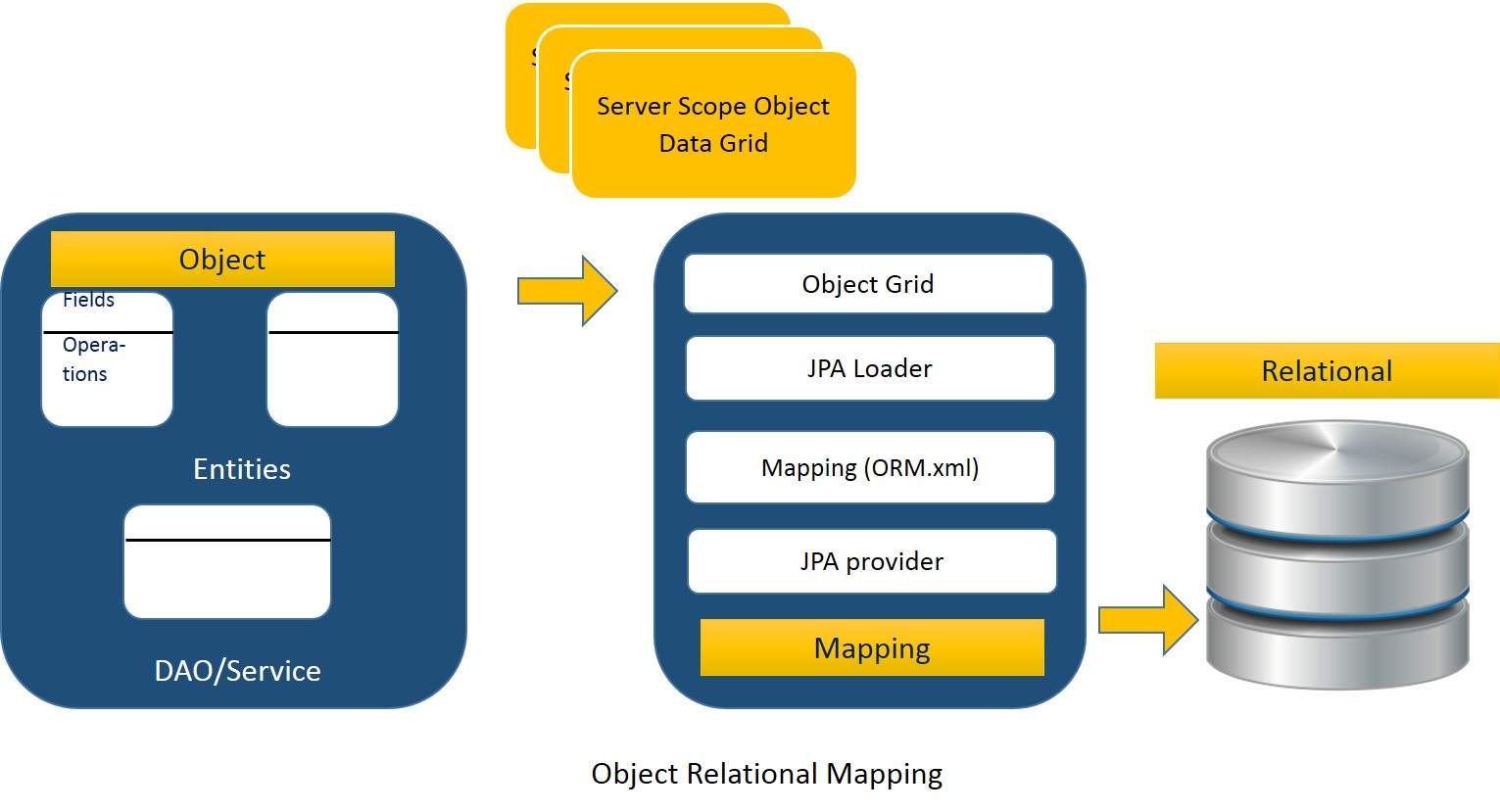
La arquitectura se explica cmo datos del objeto se almacenan en bases de datos relacionales en tres fases.
Fase1
La primera fase, denominada fase de datos del objeto, contiene las clases POJO, interfaces y clases. Es el principal componente de empresa de capa, que tiene lgica de negocios operaciones y atributos.
Por ejemplo, vamos a tener una base de datos de empleados como esquema.
POJO empleado clase contiene atributos como ID, nombre, salario, y designacin. Tambin contiene mtodos setter y getter de esos atributos.
Empleado DAO/clases de servicio contienen mtodos de servicio tales como crear empleado, encontrar los empleados y eliminar empleado.
Fase 2
La segunda fase, denominada fase de mapeo o persistencia JPA proveedor, contiene, archivo de mapas (ORM.xml), JPA Cargadora y rejilla de objeto.
JPA Provider : es el producto de proveedor que contiene el JPA sabor (javax.persistence). Por ejemplo Eclipselink, Toplink, hibernacin, etc.
Archivo de asignacin : El archivo de asignacin (ORM.xml) contiene configuracin de la asignacin entre los datos de un POJO clase y los datos en una base de datos relacional.
JPA Cargador cargador : La APP funciona como una memoria cach. Puede cargar los datos relacionales. Funciona como una copia de base de datos para interactuar con las clases de servicio de datos POJO POJO (atributos de clase).
Rejilla de Objeto : es una ubicacin temporal que puede almacenar una copia de los datos relacionales, como una memoria cach. Todas las consultas en la base de datos se efectuar, primero en los datos del objeto grid. Slo despus de que se ha comprometido, que afecta a la base de datos principal.
Fase 3
La tercera fase es la fase de datos relacionales. Contiene los datos relacionales que lgicamente est conectado al componente comercial. Como se ha indicado anteriormente, slo cuando el componente comercial se compromete los datos, que se almacenan en la base de datos fsicamente. Hasta entonces, los datos modificados se almacenan en una memoria cach como un formato de cuadrcula. El proceso de obtencin de los datos es idntica a la de almacenar los datos.
El mecanismo de la interaccin mediante programacin por encima de tres fases se denomina asignacin objeto-relacional.
Mapping.xml
La asignacin de archivo.xml es el de instruir a la JPA proveedor mapa las clases de entidad con las tablas de la base de datos.
Tomemos un ejemplo del Empleado entidad que contiene cuatro atributos. El POJO entidad clase de empleados Employee.java es la siguiente:
public class Employee
{
private int eid;
private String ename;
private double salary;
private String deg;
public Employee(int eid, String ename, double salary, String deg)
{
super( );
this.eid = eid;
this.ename = ename;
this.salary = salary;
this.deg = deg;
}
public Employee( )
{
super();
}
public int getEid( )
{
return eid;
}
public void setEid(int eid)
{
this.eid = eid;
}
public String getEname( )
{
return ename;
}
public void setEname(String ename)
{
this.ename = ename;
}
public double getSalary( )
{
return salary;
}
public void setSalary(double salary)
{
this.salary = salary;
}
public String getDeg( )
{
return deg;
}
public void setDeg(String deg)
{
this.deg = deg;
}
}
El cdigo anterior es la entidad Employee clase POJO. Contiene cuatro atributos b>eid, ename, salary, and deg. Considerar estos atributos como los campos de tabla en una tabla y eid como clave principal de la tabla. Ahora tenemos que tener en cuenta en el diseo del archivo de asignacin para hibernar. Nombre del archivo de mapas mapping.xml es el siguiente:
<? xml version="1.0" encoding="UTF-8" ?>
<entity-mappings xmlns="http://java.sun.com/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence/orm
http://java.sun.com/xml/ns/persistence/orm_1_0.xsd"
version="1.0">
<description> XML Mapping file</description>
<entity class="Employee">
<table name="EMPLOYEETABLE"/>
<attributes>
<id name="eid">
<generated-value strategy="TABLE"/>
</id>
<basic name="ename">
<column name="EMP_NAME" length="100"/>
</basic>
<basic name="salary">
</basic>
<basic name="deg">
</basic>
</attributes>
</entity>
</entity-mappings>
La secuencia de comandos anterior se utiliza para la cartografa de la clase de entidad con la tabla de la base de datos. En este archivo
<entity-mappings> etiqueta define la definicin de esquema para permitir etiquetas de entidad en archivo xml.
<description> : etiqueta ofrece una descripcin acerca de la aplicacin.
<entity> : etiqueta define la clase de entidad que desea convertir en una tabla en una base de datos. Clase de atributo POJO define el nombre de la clase de entidad.
<table> : etiqueta define el nombre de la tabla. Si desea tener nombres idnticos tanto para la clase, as como la tabla y, a continuacin, esta etiqueta no es necesario.
<attributes> : etiqueta define los atributos (campos de una tabla).
<id> : etiqueta define la clave principal de la tabla. El <genera valor de etiqueta> define cmo asignar el valor de la clave principal como automtica, manual o de secuencia.
<basic> : etiqueta se utiliza para definir los atributos de la tabla.
<column-name> : etiqueta se usa para definir tabla definidas por el usuario nombres de campo en la tabla.
Las anotaciones
Por lo general se utilizan archivos xml para configurar los componentes especficos, o asignacin de dos diferentes especificaciones de los componentes. En nuestro caso, tenemos que mantener archivos xml por separado en un marco. Eso significa que al escribir un archivo de asignacin xml, necesitamos comparar los atributos de clase POJO con las etiquetas de la entidad en el archivo mapping.xml.
Aqu est la solucin. En la definicin de la clase, podemos escribir la configuracin con anotaciones. Las anotaciones se utilizan para las clases, propiedades y mtodos. Las anotaciones comienzan con " @" el smbolo. Las anotaciones son declarados antes de una clase, propiedad o mtodo. Todas las anotaciones de JPA se definen en el javax.persistence paquete
Aqu lista de anotaciones utilizadas en nuestros ejemplos se dan a continuacin.
| Anotacin | Descripcin |
|---|---|
| @Entidad | Declara la clase como una entidad o una tabla. |
| @Tabla | Declara nombre de la tabla. |
| @Basic | Especifica no campos de restriccin explcita. |
| @Embedded | Especifica las propiedades de la clase o de una entidad cuyo valor es una instancia de una clase se puede incrustar. |
| @Id | Especifica la propiedad, el uso de la identidad (la clave principal de una tabla de la clase. |
| @GeneratedValue | Especifica el modo en que la identidad se puede inicializar atributo como automtica, manual o valor tomado de la tabla de secuencias. |
| @Transitorios | Especifica la propiedad que no es constante, es decir, el valor nunca se almacena en la base de datos. |
| @Columna | Especifica el atributo de columna para la propiedad persistence. |
| @SequenceGenerator | Especifica el valor de la propiedad que se especifica en la anotacin @GeneratedValue. Crea una secuencia. |
| @TableGenerator | Especifica el generador de valor para la propiedad especificada en la anotacin @GeneratedValue. Crea una tabla de generacin de valor. |
| @AccessType | Este tipo de anotacin se utiliza para establecer el tipo de acceso. Si establece el valor de @mtodos Accesstype() y formattype() CAMPO), luego se produce acceso Campo sabio. Si establece el valor de @mtodos Accesstype() y formattype() PROPIEDAD), a continuacin, el acceso se produce bienes. |
| @JoinColumn | Especifica la entidad asociacin o entidad coleccin. Esto se utiliza en muchos-a-uno y uno-a-muchas asociaciones. |
| @UniqueConstraint | Especifica los campos y las restricciones unique para la primaria o la secundaria. |
| @ColumnResult | Hace referencia al nombre de una columna de la consulta SQL que utiliza clusula select. |
| @ManyToMany | Define una relacin many-to-many entre el unir tablas. |
| @ManyToOne | Define una relacin de many-to-one entre el unir tablas. |
| @OneToMany | Define una relacin one-to-many entre los unir tablas. |
| @OneToOne | Define una relacin one-to-one entre los unir tablas. |
| @NamedQueries | Especifica la lista de consultas con nombre. |
| @NamedQuery | Especifica una consulta con nombre esttico. |
Estndar Java Bean
La clase Java encapsula los valores de instancia y sus comportamientos en una sola unidad llamada objeto. Java Bean es un almacenamiento temporal y componentes reutilizables o de un objeto. Se trata de una clase serializable que tiene un constructor predeterminado y mtodos get y set para inicializar los atributos de la instancia individual.
Bean Convenios
Frijol contiene su constructor predeterminado o un archivo que contiene serializa la instancia. Por lo tanto, un frijol puede crear una instancia de otro grano.
Las propiedades de un frijol pueden ser segregadas en propiedades booleanas o no booleano.
Propiedad booleanos no contiene getter y setter mtodos.
Propiedad booleana contienen setter y es mtodo.
Getter mtodo de cualquier propiedad debe comenzar con pequeas Letras get (java method convention) y continu con un nombre de campo que comienza con mayscula. Por ejemplo, el nombre del campo es salario por tanto el mtodo getter de este campo es getSalary ().
Setter mtodo de cualquier propiedad debe comenzar con pequeas Letras set (java method convention), continu con un nombre de campo que comienza con letra mayscula y el argument value para establecer en campo. Por ejemplo, el nombre del campo es salario por tanto el mtodo setter de este campo es setSalary ( double sal ).
Para propiedad booleana, is mtodo para comprobar si es verdadero o falso. Por ejemplo la propiedad booleana vaco, el es mtodo de este campo es isEmpty ().