- IMS DB - Inicio
- IMS DB - Descripción General
- IMS DB - Estructura
- IMS DB - DL/I Terminología
- IMS DB - DL/I Procesamiento
- IMS DB - Bloques de Control
- IMS DB - Programación
- IMS DB - Cobol Básico
- IMS DB - DL/I Funciones
- IMS DB - PCB máscara
- IMS DB - SSA
- IMS DB - Recuperación de Datos
- IMS DB - Manipulación de Datos
- IMS DB - Índice Secundario
- IMS DB - Base de datos lógica
- IMS DB - Recuperación
- IMS DB - Preguntas de la entrevist
IMS DB - DL/I Procesamiento
IMS DB almacena los datos en diferentes niveles. Los datos se recuperan y se inserta por emitir DL/I, se pide desde un programa de aplicacin. Vamos a debatir acerca de DL/I, se pide en detalle en los prximos captulos. Los datos se procesan las dos formas siguientes:
- Procesamiento Secuencial
- Procesamiento aleatorio
Procesamiento Secuencial
Cuando los segmentos se recuperan secuencialmente desde la base de datos, DL/I sigue un modelo predefinido. Nos permiten entender el procesamiento secuencial de IMS.
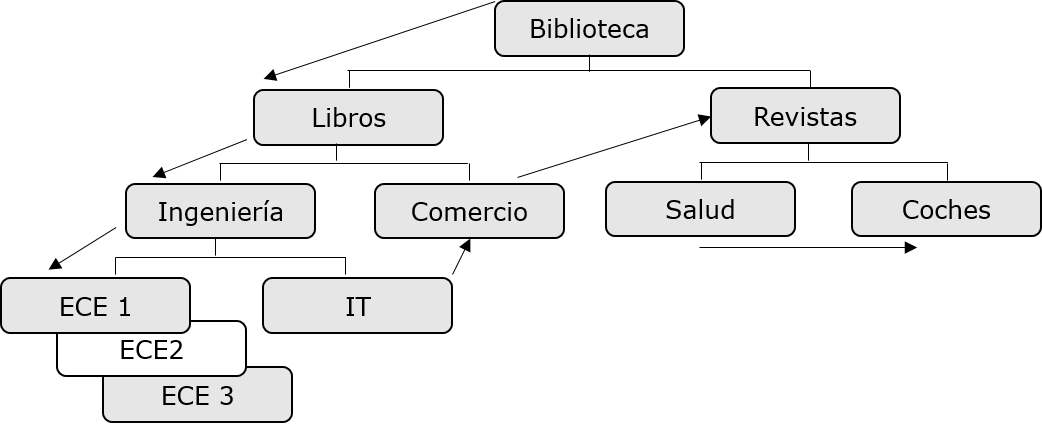
A continuacin se enumeran los puntos a tener en cuenta acerca de procesamiento secuencial:
Modelo predefinido para tener acceso a los datos de DL/I es el primero en la jerarqua, y a la izquierda a la derecha.
El segmento raz se recupera en primer lugar, a continuacin, DL/I se desplaza a la izquierda en la primera infancia y se va hasta el nivel ms bajo. En el nivel ms bajo, recupera todas las apariciones de dos segmentos. Luego pasa al derecho.
Para comprenderlo mejor, observar las flechas en la figura anterior que muestran el flujo de acceso a los segmentos. Biblioteca es la raz y el segmento el flujo comienza desde all y va hasta los coches para obtener acceso a un nico registro. El mismo proceso se repite para todas las ocurrencias de obtener todos los registros de datos.
Al acceder a los datos, el programa utiliza la posicin en la base de datos que ayuda a recuperar y insertar segmentos.
Procesamiento aleatorio
Procesamiento aleatorio tambin se conoce como transformacin directa de los datos de IMS. Veamos un ejemplo para comprender procesamiento aleatorio en IMS DB :
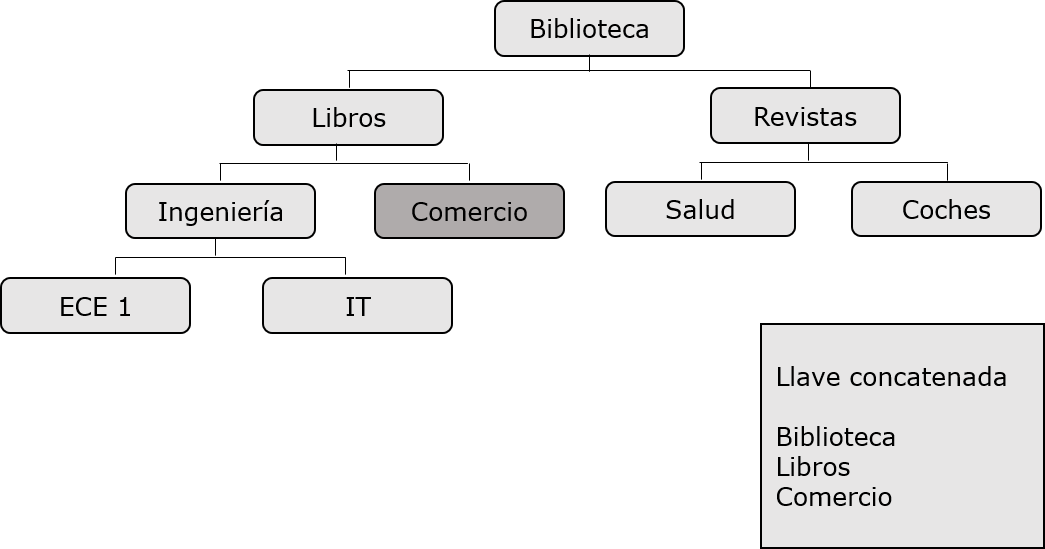
A continuacin se enumeran los puntos a tener en cuenta acerca de procesamiento aleatorio:
Segmento que es necesario recuperar al azar requiere campos clave en todos los segmentos que depende de. Estos campos clave son suministrados por el programa de aplicacin.
Una clave concatenada completamente identifica la ruta de acceso desde la raz hacia el segmento segmento que desea recuperar.
Supongamos que desea recuperar una aparicin del comercio electrnico, a continuacin, usted tendr que proporcionar la clave concatenada valores de campo de los segmentos depende de, tales como la Biblioteca, libros, y el comercio.
Procesamiento Aleatorio es ms rpida de procesamiento secuencial. En escenario real, de las aplicaciones secuenciales y combinar ambos mtodos de procesamiento aleatorio juntos para lograr mejores resultados.
Campo clave
Puntos a tener en cuenta:
Un campo clave tambin es conocido como un campo de secuencia.
Un campo de clave est presente en un segmento, que se utiliza para recuperar el segmento.
Un campo clave gestiona el segmento aparicin en orden ascendente.
En cada segmento, un solo campo puede ser utilizado como un campo clave o campo de secuencia.
Campo de bsqueda
Como se mencion anteriormente, un solo campo puede ser utilizado como un campo clave. Si desea buscar por el contenido de otro segmento los campos que no son campos clave, el campo que se usa para recuperar los datos es conocido como un campo de bsqueda.