- HBase - Inicio
- HBase - Descripción General
- HBase - Arquitectura
- HBase - Instalación
- HBase - Shell
- HBase - Comandos Generales
- HBase - Admin API
- HBase - Crear Tabla
- HBase - Listado Tabla
- HBase - Desactivación de una Tabla
- HBase - Permitiendo una Tabla
- HBase - Describir y Modificar
- HBase - Existe
- HBase - Soltar la Tabla
- HBase - Apagado
- HBase - API de Cliente
- HBase - Crear Datos
- HBase - Actualizar Datos
- HBase - Leer Datos
- HBase - Eliminar Datos
- HBase - Escanear
- HBase El Conde y Truncar
- HBase - Seguridad
HBase - Instalacin
Este captulo explica cmo HBase se instala y se configura inicialmente. Java y Hadoop son necesarios para proceder a HBase, as que tienes que descargar e instalar java y Hadoop en su sistema.
Configuracin previa a la instalacin
Antes de instalar Hadoop en entorno Linux, tenemos que configurar Linux usando ssh (Secure Shell). Siga los pasos que se indican a continuacin para configurar el entorno de Linux.
Creacin de un usuario
En primer lugar, se recomienda crear un usuario aparte para Hadoop Hadoop para aislar el sistema de archivos del sistema de archivos de Unix. Siga los pasos que se indican a continuacin para crear un usuario.
- Abra el usuario root utilizando el comando "su".
- Crear un usuario de la cuenta de root con el comando "useradd usuario".
- Ahora puede abrir una cuenta de usuario existente mediante el comando "su nombre".
Abrir el terminal de Linux y escriba los siguientes comandos para crear un usuario
$ su password: # useradd hadoop # passwd hadoop New passwd: Retype new passwd
Configuracin SSH y la generacin de claves
Es necesario realizar una configuracin SSH para realizar distintas operaciones en el grupo de instrumentos, como iniciar, detener, y se distribuyen las operaciones shell daemon. Para autenticar usuarios diferentes de Hadoop, es necesaria para proporcionar par de claves pblica/privada para un usuario Hadoop y compartirla con los usuarios.
Los siguientes comandos se utilizan para generar un par de clave y valor mediante SSH. Copiar las claves pblicas forma id_rsa.pub a authorized_keys, y proporcionar propietario, permisos de lectura y escritura en archivo authorized_keys, respectivamente.
$ ssh-keygen -t rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
Compruebe ssh
ssh localhost
Instalacin de Java
Java es el principal requisito previo para Hadoop, HBase. En primer lugar, debe comprobar la existencia de java en el sistema utilizando "java -version". La sintaxis de java versin comando es dada a continuacin.
$ java -version
Si todo funciona bien, se le dar el siguiente resultado.
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
Si java no est instalado en el sistema, a continuacin, siga los pasos que se indican a continuacin para instalar java.
Paso 1
Descargar Java (JDK
A continuacin, jdk-7u71-linux-x64.tar.gz se descargar en su sistema.
Paso 2
En general, encontrar el archivo descargado java en carpeta de descargas. Verificar y extraer el jdk-7u71-linux-x64.gz usando los siguientes comandos.
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
Paso 3
Para que java disponible para todos los usuarios, tiene que mover a la ubicacin /usr/local/. Abrir root y escriba los siguientes comandos.
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
Paso 4
Para la configuracin de ruta de acceso y JAVA_HOME variables, agregar los siguientes comandos en el archivo ~/.bashrc.
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH= $PATH:$JAVA_HOME/bin
Ahora compruebe que el java -version comando desde el terminal, como se explic anteriormente
Descargar Hadoop
Despus de instalar java, se tiene que instalar Hadoop. En primer lugar, verifique la existencia de Hadoop usando " Hadoop versin " comando como se muestra a continuacin.
hadoop version
Si todo funciona bien, se le dar el siguiente resultado.
Hadoop 2.6.0 Compiled by jenkins on 2014-11-13T21:10Z Compiled with protoc 2.5.0 From source with checksum 18e43357c8f927c0695f1e9522859d6a This command was run using /home/hadoop/hadoop/share/hadoop/common/hadoop-common-2.6.0.jar
Si el sistema es capaz de localizar Hadoop, Hadoop, a continuacin, descargue en su sistema. Siga los comandos que se indican a continuacin para hacerlo.
Descargar y extraer hadoop-2.6.0 de Apache Software Foundation usando los siguientes comandos.
$ su password: # cd /usr/local # wget http://mirrors.advancedhosters.com/apache/hadoop/common/hadoop- 2.6.0/hadoop-2.6.0-src.tar.gz # tar xzf hadoop-2.6.0-src.tar.gz # mv hadoop-2.6.0/* hadoop/ # exit
Instalar Hadoop
Instalar Hadoop en cualquiera de los modo necesario. Aqu estamos demostrando HBase funcionalidades en pseudo modo distribuido, por lo tanto, debe instalar Hadoop en pseudo modo distribuido.
Los siguientes pasos se utilizan para instalar Hadoop 2.4.1.
Paso 1 - Configuracin de Hadoop
Puede establecer las variables de entorno Hadoop anexar los siguientes comandos para ~/.bashrc.
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL=$HADOOP_HOME
Ahora se aplican todos los cambios en el sistema actual.
$ source ~/.bashrc
Paso 2 - Configuracin Hadoop
Usted puede encontrar todos los archivos de configuracin Hadoop en la ubicacin "$HADOOP_HOME/etc/hadoop". Usted necesita hacer cambios en los archivos de configuracin segn su Hadoop infraestructura.
$ cd $HADOOP_HOME/etc/hadoop
Con el fin de desarrollar programas en java Hadoop, tienes que reiniciar el entorno java variable en hadoop-env.sh archivo JAVA_HOME valor de sustitucin con la ubicacin de java en su sistema.
export JAVA_HOME=/usr/local/jdk1.7.0_71
Tendr que editar los archivos siguientes para configurar Hadoop.
Core-site.xml
El ncleo de sitio.xml contiene informacin como el nmero de puerto que se usa para Hadoop ejemplo, memoria asignada para sistema de archivos, lmite de memoria para almacenar datos, y el tamao de lectura/escritura.
Apertura del ncleo de sitio web.xml y agregar las siguientes propiedades en entre el <configuration> and </configuration> etiquetas.
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
Hdfs sitio.xml
La hdfs sitio.xml contiene informacin como el valor de los datos de rplica, namenode ruta y datanode camino de los sistemas de archivos locales, en la que desea almacenar el Hadoop infraestructura.
Supongamos los siguientes datos.dfs.replication (data replication value) = 1 (In the below given path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
Abra este archivo y agregar las siguientes propiedades en entre <configuracin>, < /configuration> etiquetas.
<configuration$gt; <property$gt; <name$gt;dfs.replication</name $gt; <value$gt;1</value$gt; </property$gt; <property$gt; <name$gt;dfs.name.dir</name$gt; <value$gt;file:///home/hadoop/hadoopinfra/hdfs/namenode</value$gt; </property$gt; <property$gt; <name$gt;dfs.data.dir</name$gt; <value$gt;file:///home/hadoop/hadoopinfra/hdfs/datanode</value$gt; </property$gt; </configuration$gt;
Nota: En el archivo anterior, todos los valores de la propiedad son definidos por el usuario y puede realizar cambios en funcin de su infraestructura Hadoop.
Hilo-site.xml
Este archivo se utiliza para configurar hilo en Hadoop. Abra el hilo de sitio.xml y agregar la siguiente propiedad de configuracin entre <configuration$gt;, </configuration$gt; las etiquetas de este archivo.
<configuration$gt; <property$gt; <name$gt;yarn.nodemanager.aux-services</name$gt; <value$gt;mapreduce_shuffle</value$gt; </property$gt; </configuration$gt;
Mapred sitio.xml
Este archivo se utiliza para especificar qu MapReduce framework que estamos usando. De forma predeterminada, Hadoop contiene una plantilla de yarn-site.xml. En primer lugar, es necesario copiar el archivo desde mapred de sitio web.xml.plantilla para mapred sitio.xml con el siguiente comando.
$ cp mapred-site.xml.template mapred-site.xml
Mapred Abierto de sitio.xml y agregar las siguientes propiedades en entre el <configuration> y < /configuration> etiquetas.
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Hadoop Instalacin Verificacin
Los siguientes pasos se utilizan para verificar la instalacin Hadoop.
Paso 1 - Instalacin del nodo Nombre
Configurar el namenode usando el comando "hdfs namenode -format" de la siguiente manera
$ cd ~ $ hdfs namenode -format
El resultado esperado es la siguiente.
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
Paso 2 - Verificar Hadoop dfs
El siguiente comando se utiliza para iniciar sle. Al ejecutar este comando, se iniciar la Hadoop sistema de archivos.
$ start-dfs.sh
El resultado esperado es la siguiente
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop- 2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
Paso 3 - Verificar Hilo Script
El siguiente comando se utiliza para iniciar el hilo script. Al ejecutar este comando se inicie el hilo demonios.
$ start-yarn.sh
El resultado esperado es la siguiente
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out localhost: starting nodemanager, logging to /home/hadoop/hadoop- 2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
Paso 4 - Acceder a Hadoop en el navegador
El nmero de puerto predeterminado para acceder a Hadoop es 50070. Utilice la siguiente direccin url para obtener servicios Hadoop en su navegador.
http://localhost:50070
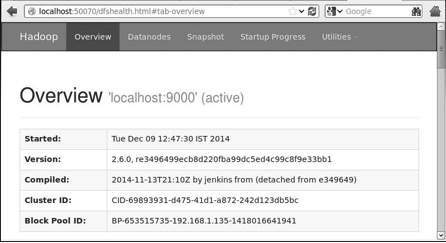
Paso 5 - Verificar que todas las aplicaciones de clster
El nmero de puerto predeterminado para acceder a todas las aplicaciones de clster es 8088. Utilice la siguiente direccin url para visitar este servicio.
http://localhost:8088/
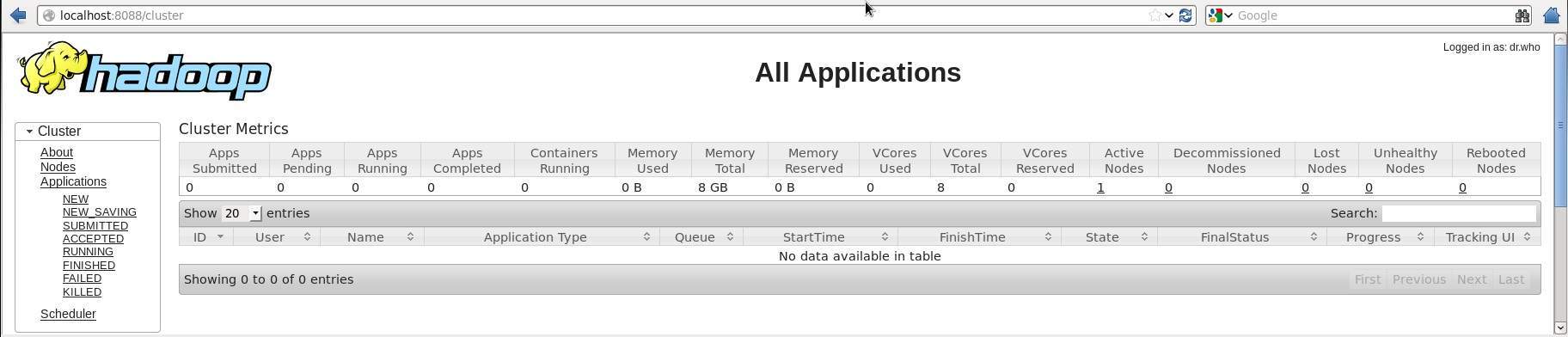
Instalar HBase
Podemos instalar HBase en cualquiera de los tres modos: modo autnomo, Pseudo modo distribuido, y Totalmente modo distribuido.
Instalar HBase en modo autnomo
Descargar la ltima versin estable de forma HBase http://www.interiordsgn.com/apache/hbase/stable/ utilizando "wget" comando y extraerla mediante la tar zxvf "" comando. Consulte el siguiente comando.
$cd usr/local/ $wget http://www.interior-dsgn.com/apache/hbase/stable/hbase-0.98.8- hadoop2-bin.tar.gz $tar -zxvf hbase-0.98.8-hadoop2-bin.tar.gz
Cambiar a modo sper usuario y mueva el HBase carpeta en /usr/local, como se muestra a continuacin.
$su $password: enter your password here mv hbase-0.99.1/* Hbase/
HBase inStandalone Modo Configuracin
Antes de proceder a HBase, tiene que editar los siguientes archivos y configurar HBase.
Hbase-env.sh
Establecer el inicio de java para HBase hbase y abierto-env.sh archivo de la carpeta conf. Editar variable de entorno JAVA_HOME y cambiar la ruta existente a su actual variable JAVA_HOME como se muestra a continuacin.
cd /usr/local/Hbase/conf gedit hbase-env.sh
As se abrir el env.sh archivo de HBase. Ahora sustituir la actual JAVA_HOME valor con el valor actual, como se muestra a continuacin.
export JAVA_HOME=/usr/lib/jvm/java-1.7.0
Hbase sitio.xml
Este es el archivo principal de configuracin de HBase. Establece el directorio de datos en la ubicacin adecuada de la apertura de la HBase carpeta de inicio en /usr/local/HBase. Dentro de la carpeta conf, encontrar varios archivos, abra el hbase-site.xml archivo xml como se muestra a continuacin.
#cd /usr/local/HBase/ #cd conf # gedit hbase-site.xml
Hbase dentro del sitio.xml, se encuentra el <configuration> y < /configuration> etiquetas. Dentro de ellos, el HBase directorio en la clave de la propiedad con el nombre de "hbase.rootdir" como se muestra a continuacin.
<configuration> //Here you have to set the path where you want HBase to store its files. <property> <name>hbase.rootdir</name> <value>file:/home/hadoop/HBase/HFiles</value> </property> //Here you have to set the path where you want HBase to store its built in zookeeper files. <property> <name>hbase.zookeeper.property.dataDir</name> <value>/home/hadoop/zookeeper</value> </property> </configuration>
Con esto, la instalacin y configuracin HBase parte se ha completado correctamente. Podemos comenzar con start-hbase.sh en la carpeta bin de HBase. Para ello, abrir carpeta de inicio HBase HBase y ejecutar script de inicio como se muestra a continuacin.
$cd /usr/local/HBase/bin $./start-hbase.sh
Si todo va bien, cuando intenta ejecutar HBase script de inicio, aparecer un mensaje diciendo que HBase ha comenzado.
starting master, logging to /usr/local/HBase/bin/../logs/hbase-tpmaster-localhost.localdomain.out
HBase Instalacin en modo Pseudo-Distributed
Ahora comprobar cmo HBase es instalado en pseudo-modo distribuido.
Configuracin HBase
Antes de proceder con Hadoop HBase, configurar y HDFS en el sistema local o en un sistema remoto y asegrese de que se estn ejecutando. HBase parada si se est ejecutando.
Hbase-sitio.xml
Editar hbase-sitio.xml para agregar las siguientes propiedades.
<property> <name>hbase.cluster.distributed</name> <value>true</value> </property>
Se menciona en qu modo HBase debe ejecutarse. En el mismo archivo del sistema de archivos local, cambiar el hbase.rootdir HDFS, su direccin, utilizando la hdfs://// sintaxis de URI. Estamos ejecutando HDFS en el localhost en el puerto 8030.
<property> <name>>hbase.rootdir</name> <value>hdfs://localhost:8030/hbase</value> </property>
HBase Inicio
Despus de la configuracin, vaya a carpeta de inicio HBase HBase y comenzar con el siguiente comando.
$cd /usr/local/HBase $bin/start-hbase.sh
Nota: Antes de comenzar HBase, asegrese de que Hadoop est en marcha.
Controlar el HBase HDFS en directorio
HBase crea su directorio en HDFS. Para ver el directorio creado, vaya a Hadoop bin y escriba el siguiente comando
$ ./bin/hadoop fs -ls /hbase
Si todo va bien, se le dar el siguiente resultado.
Found 7 items drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/.tmp drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/WALs drwxr-xr-x - hbase users 0 2014-06-25 18:48 /hbase/corrupt drwxr-xr-x - hbase users 0 2014-06-25 18:58 /hbase/data -rw-r--r-- 3 hbase users 42 2014-06-25 18:41 /hbase/hbase.id -rw-r--r-- 3 hbase users 7 2014-06-25 18:41 /hbase/hbase.version drwxr-xr-x - hbase users 0 2014-06-25 21:49 /hbase/oldWALs
Iniciar y detener un maestro
Mediante el "local-master-backup.sh" usted puede comenzar hasta 10 servidores. Abra la carpeta de inicio de HBase, master y ejecute el siguiente comando para iniciar el programa.
$ ./bin/local-master-backup.sh 2 4
Para matar a una copia de seguridad de master, que necesita su id de proceso, que se almacenan en un archivo denominado"/tmp/hbase-USER-X-master.pid."usted puede matar la unidad maestra de reserva con el siguiente comando.
$ cat /tmp/hbase-user-1-master.pid |xargs kill -9
Arranque y parada RegionServers
Puede ejecutar varios servidores de regin en un solo sistema con el siguiente comando.
$ .bin/local-regionservers.sh start 2 3
Para detener un servidor de regin, utilice el siguiente comando.
$ .bin/local-regionservers.sh stop 3
A partir HBaseShell
A continuacin, se presentan la secuencia de pasos que se deben seguir antes de iniciar el HBase shell. Abrir el terminal, e inicie sesin como super usuario.
Strat Hadoop Sistema de archivos
Navegar por Hadoop casa sbin carpeta y Hadoop inicio sistema de archivos como se muestra a continuacin.
$cd $HADOOP_HOME/sbin $start-all.sh
HBase Inicio
Navegar a travs del directorio raz HBase carpeta bin y inicio HBase.
$cd /usr/local/HBase $./bin/start-hbase.sh
Inicio HBase Servidor Maestro
Este ser el mismo directorio. Inicio tal y como se muestra a continuacin
$./bin/local-master-backup.sh start 2 (number signifies specific server.)
Inicio Regin
Iniciar el servidor como se muestra a continuacin.
$./bin/./local-regionservers.sh start 3
Inicio HBase Shell
Puede iniciar HBase shell mediante el siguiente comando
$cd bin $./hbase shell
Esto le dar la HBase Intrprete de comandos del Shell, como se muestra a continuacin.
2014-12-09 14:24:27,526 INFO [main] Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available HBase Shell; enter 'help<RETURN>' for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 0.98.8-hadoop2, r6cfc8d064754251365e070a10a82eb169956d5fe, Fri Nov 14 18:26:29 PST 2014 hbase(main):001:0>
HBase Interfaz Web
Para acceder a la interfaz web de HBase, escriba la siguiente direccin url en el explorador
http://localhost:60010
Esta interfaz muestra la regin est ejecutando servidores de copia de seguridad del maestro HBase y tablas.
HBase servidores de regin y de copia de seguridad del maestro
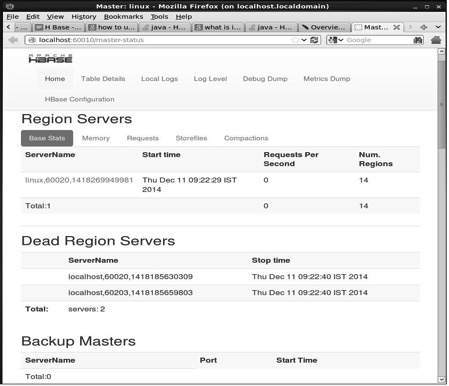
HBase Tablas
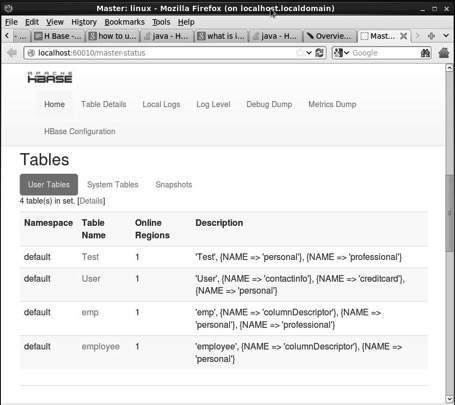
Ajuste entorno Java
Tambin podemos comunicar con HBase utilizando las bibliotecas de Java, pero antes de acceder a HBase utilizando la API de Java que necesita set classpath para dichas bibliotecas.
Configuracin del Classpath.
Antes de continuar con la programacin, el classpath a HBase bibliotecas en .bashrc archivo .Abrir un .bashrc en cualquiera de los editores como se muestra a continuacin.
$ gedit ~/.bashrc
HBase Set classpath para bibliotecas (lib carpeta HBase) en tal y como se muestra a continuacin.
export CLASSPATH=$CLASSPATH://home/hadoop/hbase/lib/*
Esto es para evitar que la "clase" (no se ha encontrado la excepcin al acceder a HBase utilizando la API de java.