- DWH - Home
- DWH - Overview
- DWH - Concepts
- DWH - Terminologies
- DWH - Delivery Process
- DWH - System Processes
- DWH - Architecture
- DWH - OLAP
- DWH - Relational OLAP
- DWH - Multidimensional OLAP
- DWH - Schemas
- DWH - Partitioning Strategy
- DWH - Metadata Concepts
- DWH - Data Marting
- DWH - System Managers
- DWH - Process Managers
- DWH - Security
- DWH - Backup
- DWH - Tuning
- DWH - Testing
- DWH - Future Aspects
- DWH - Interview Questions
Data Warehousing - Terminologies
In this chapter, we will discuss some of the most commonly used terms in data warehousing.
Metadata
Metadata is simply defined as data about data. The data that are used to represent other data is known as metadata. For example, the index of a book serves as a metadata for the contents in the book. In other words, we can say that metadata is the summarized data that leads us to the detailed data.
In terms of data warehouse, we can define metadata as following −
Metadata is a road-map to data warehouse.
Metadata in data warehouse defines the warehouse objects.
Metadata acts as a directory. This directory helps the decision support system to locate the contents of a data warehouse.
Metadata Repository
Metadata repository is an integral part of a data warehouse system. It contains the following metadata −
Business metadata − It contains the data ownership information, business definition, and changing policies.
Operational metadata − It includes currency of data and data lineage. Currency of data refers to the data being active, archived, or purged. Lineage of data means history of data migrated and transformation applied on it.
Data for mapping from operational environment to data warehouse − It metadata includes source databases and their contents, data extraction, data partition, cleaning, transformation rules, data refresh and purging rules.
The algorithms for summarization − It includes dimension algorithms, data on granularity, aggregation, summarizing, etc.
Data Cube
A data cube helps us represent data in multiple dimensions. It is defined by dimensions and facts. The dimensions are the entities with respect to which an enterprise preserves the records.
Illustration of Data Cube
Suppose a company wants to keep track of sales records with the help of sales data warehouse with respect to time, item, branch, and location. These dimensions allow to keep track of monthly sales and at which branch the items were sold. There is a table associated with each dimension. This table is known as dimension table. For example, "item" dimension table may have attributes such as item_name, item_type, and item_brand.
The following table represents the 2-D view of Sales Data for a company with respect to time, item, and location dimensions.
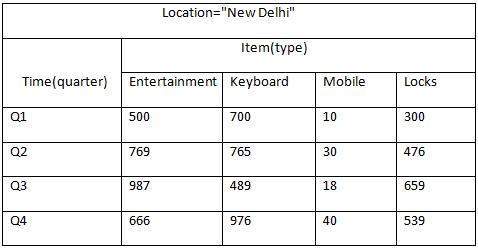
But here in this 2-D table, we have records with respect to time and item only. The sales for New Delhi are shown with respect to time, and item dimensions according to type of items sold. If we want to view the sales data with one more dimension, say, the location dimension, then the 3-D view would be useful. The 3-D view of the sales data with respect to time, item, and location is shown in the table below −
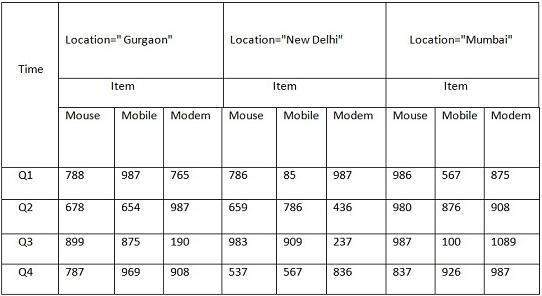
The above 3-D table can be represented as 3-D data cube as shown in the following figure −
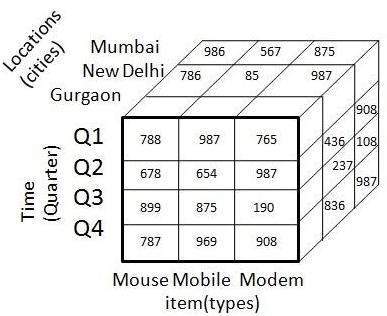
Data Mart
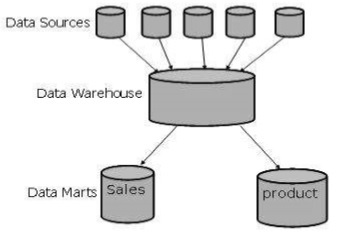
Data marts contain a subset of organization-wide data that is valuable to specific groups of people in an organization. In other words, a data mart contains only those data that is specific to a particular group. For example, the marketing data mart may contain only data related to items, customers, and sales. Data marts are confined to subjects.
Points to Remember About Data Marts
Windows-based or Unix/Linux-based servers are used to implement data marts. They are implemented on low-cost servers.
The implementation cycle of a data mart is measured in short periods of time, i.e., in weeks rather than months or years.
The life cycle of data marts may be complex in the long run, if their planning and design are not organization-wide.
Data marts are small in size.
Data marts are customized by department.
The source of a data mart is departmentally structured data warehouse.
Data marts are flexible.
The following figure shows a graphical representation of data marts.
Virtual Warehouse
The view over an operational data warehouse is known as virtual warehouse. It is easy to build a virtual warehouse. Building a virtual warehouse requires excess capacity on operational database servers.
