- IMS DB - Home
- IMS DB - Overview
- IMS DB - Structure
- IMS DB - DL/I Terminology
- IMS DB - DL/I Processing
- IMS DB - Control Blocks
- IMS DB - Programming
- IMS DB - Cobol Basics
- IMS DB - DL/I Functions
- IMS DB - PCB Mask
- IMS DB - SSA
- IMS DB - Data Retrieval
- IMS DB - Data Manipulation
- IMS DB - Secondary Indexing
- IMS DB - Logical Database
- IMS DB - Recovery
IMS DB - Secondary Indexing
Secondary Indexing is used when we want to access a database without using the complete concatenated key or when we do not want to use the sequence primary fields.
Index Pointer Segment
DL/I stores the pointer to segments of the indexed database in a separate database. Index pointer segment is the only type of secondary index. It consists of two parts −
- Prefix Element
- Data Element
Prefix Element
The prefix part of the index pointer segment contains a pointer to the Index Target Segment. Index target segment is the segment that is accessible using the secondary index.
Data Element
The data element contains the key value from the segment in the indexed database over which the index is built. This is also known as the index source segment.
Here are the key points to note about Secondary Indexing −
The index source segment and the target source segment need not be the same.
When we set up a secondary index, it is automatically maintained by the DL/I.
The DBA defines many secondary indexes as per the multiple access paths. These secondary indexes are stored in a separate index database.
We should not create more secondary indexes, as they impose additional processing overhead on the DL/I.
Secondary Keys
Points to note −
The field in the index source segment over which the secondary index is built is called as the secondary key.
Any field can be used as a secondary key. It need not be the segments sequence field.
Secondary keys can be any combination of single fields within the index source segment.
Secondary key values do not have to be unique.
Secondary Data Structures
Points to note −
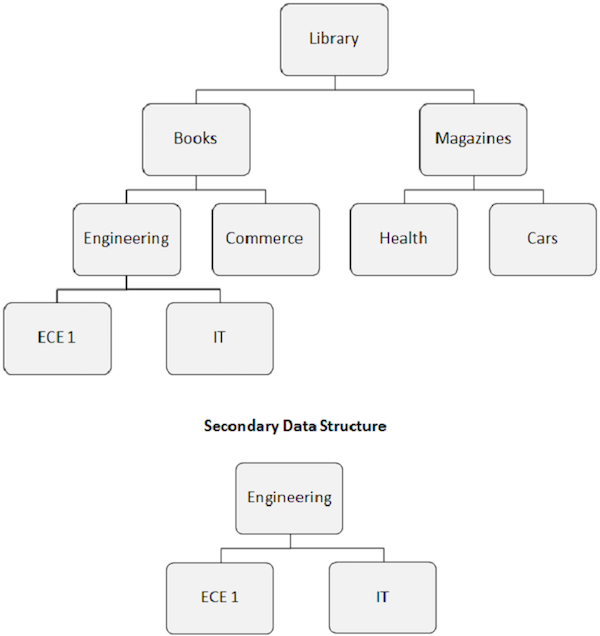
When we build a secondary index, the apparent hierarchical structure of the database is also changed.
The index target segment becomes the apparent root segment. As shown in the following image, the Engineering segment becomes the root segment, even if it is not a root segment.
The rearrangement of the database structure caused by the secondary index is known as the secondary data structure.
Secondary data structures do not make any changes to the main physical database structure present on the disk. It is just a way to alter the database structure in front of the application program.
Independent AND Operator
Points to note −
When an AND (* or &) operator is used with secondary indexes, it is known as a dependent AND operator.
An independent AND (#) allows us to specify qualifications that would be impossible with a dependent AND.
This operator can be used only for secondary indexes where the index source segment is dependent on the index target segment.
We can code an SSA with an independent AND to specify that an occurrence of the target segment be processed based on the fields in two or more dependent source segments.
01 ITEM-SELECTION-SSA.
05 FILLER PIC X(8).
05 FILLER PIC X(1) VALUE '('.
05 FILLER PIC X(10).
05 SSA-KEY-1 PIC X(8).
05 FILLER PIC X VALUE '#'.
05 FILLER PIC X(10).
05 SSA-KEY-2 PIC X(8).
05 FILLER PIC X VALUE ')'.
Sparse Sequencing
Points to note −
Sparse sequencing is also known as Sparse Indexing. We can remove some of the index source segments from the index using sparse sequencing with secondary index database.
Sparse sequencing is used to improve the performance. When some occurrences of the index source segment are not used, we can remove that.
DL/I uses a suppression value or a suppression routine or both to determine whether a segment should be indexed.
If the value of a sequence field in the index source segment matches a suppression value, then no index relationship is established.
The suppression routine is a user-written program that evaluates the segment and determines whether or not it should be indexed.
When sparse indexing is used, its functions are handled by the DL/I. We do not need to make special provisions for it in the application program.
DBDGEN Requirements
As discussed in earlier modules, DBDGEN is used to create a DBD. When we create secondary indexes, two databases are involved. A DBA needs to create two DBDs using two DBDGENs for creating a relationship between an indexed database and a secondary indexed database.
PSBGEN Requirements
After creating the secondary index for a database, the DBA needs to create the PSBs. PSBGEN for the program specifies the proper processing sequence for the database on the PROCSEQ parameter of the PSB macro. For the PROCSEQ parameter, the DBA codes the DBD name for the secondary index database.