- Computer Vision - Home
- Computer Vision - Introduction
- Computer Vision - Fundamentals of Image Processing
- Computer Vision - Image Segmentation
- Computer Vision - Image Preprocessing Techniques
- Computer Vision - Feature Detection and Extraction
- Computer Vision - Object Detection
- Computer Vision - Image Classification
- Computer Vision - Image Recognition and Matching
- Computer Vision Useful Resources
- Computer Vision - Useful Resources
- Computer Vision - Discussion
Computer Vision - Image Recognition and Matching
Computer vision is a field of artificial intelligence (AI) that enables machines to interpret and make decisions based on visual data as same as human vision. It involves acquiring, processing, analyzing and understanding images or videos to extract meaningful information. There are two important subdomains in Computer Vision which are as follows −
- Image Recognition: This is the process of identifying objects, patterns or features in an image.
- Image Matching This is the process of comparing and finding similarities between two or more images.
The above two techniques are widely used in various applications such as facial recognition, object detection, medical imaging, augmented reality (AR) and robotics.
In this chapter we are going to learn about Image Recognition and Image Matching in detail.
Image Recognition
Image Recognition is a fundamental task in computer vision which enable machines to identify and categorize objects in images or videos. It involves analyzing pixel data, extracting patterns and classifying visual information using machine learning (ML) and deep learning (DL) techniques. This capability of Image Recognition is widely used in autonomous vehicles, facial recognition, medical diagnostics, security systems and industrial automation.
Key Components of Image Recognition
Following are the key components of Image Recognition in Computer Vision −
- Image Preprocessing: This is one of the crucial steps in image recognition which enhances image quality and prepares data for feature extraction and classification. It ensures that models receive clean, standardized and optimized images by improving accuracy and efficiency.
- Feature Extraction: It is a step in image recognition where meaningful patterns, edges, textures and key points are identified from an image. These extracted features are then used for object detection, classification and pattern recognition. This can be done using traditional computer vision techniques such as edge detection and keypoint descriptors or deep learning-based methods such as Convolutional Neural Networks.
- Image classification: This is a fundamental task in computer vision that involves assigning a label or category to an image based on its content. It is widely used in applications such as face recognition, medical diagnosis, self-driving cars and object detection. There are main approaches to image classification −
- Traditional Machine Learning-Based Classification using manually extracted features such as SIFT, HOG and ORB.
- Deep Learning-Based Classification using CNNs, Vision Transformers and pre-trained models
Steps in Image Recognition
To perform Image Recognition we need to follow the steps as mentioned below −
Image Acquisition and Preprocessing
Before analyzing an image, it must be cleaned and prepared.Here are the Preprocessing techniques of Image Recognition −
- Resizing & Normalization: It is the process of standardizing image size and pixel values.
- Data Augmentation: This is a technique used in computer vision to artificially increase the size of a dataset by applying transformations to existing images. The commonly used techniques such as rotation, flipping, cropping and contrast adjustments which helps to improve model robustness.
- Noise Reduction:It is the process of removing unwanted distortions i.e., noise from images while preserving important features. Noise can be caused by low-light conditions, sensor imperfections or transmission errors. By using filters like Gaussian blur we can remove image noise.
- Color Space Conversion: This is the process of converting RGB images to grayscale when color information is unnecessary.
Feature Extraction
Feature extraction identifies key attributes of an image such as edges, shapes and textures. Following are the methods used to perform Feature Extraction −
- Edge Detection: This method detects the object boundaries by identifying sudden intensity changes. The commonly used techniques are Canny and Sobel.
- Histogram of Oriented Gradients (HOG): It extracts structural features by computing gradient orientations.
- Keypoint Detection: This method detects unique points in an image for object tracking and recognition. The Keypoint Detection can be done by using the techniques such as SIFT, ORB, SURF.
Classification using Machine Learning or Deep Learning
Image classification is the process of assigning a label or category to an image based on its visual features. It is widely used in object detection, medical imaging and facial recognition. Here are the approaches −
- Machine Learning Approach: This uses handcrafted features such as edges, shapes and textures to classify images.
- Deep Learning Approach: This uses neural networks such as CNNs, Transformers to automatically learn features.
Training the Model
Model training is the process of teaching an algorithm to recognize patterns in images by feeding it labeled data. The model learns by adjusting its parameters i.e., weights and biases to minimize classification errors. Here are the training methods −
- Supervised Learning: In this model the data is trained on labeled datasets i.e., ImageNet, COCO.
- Transfer Learning: This model can be trained with the pretrained models and fine-tuning them for specific tasks.
Prediction and Inference
The trained model analyzes new images and predicts object categories based on learned patterns.
Example of Image Recognition
In this example, we are using the Computer Vision library to perform the Image Recognition of the given input image −
import cv2
import numpy as np
# Load reference and test images in grayscale
reference_image = cv2.imread("tutorialspoint.jpg", cv2.IMREAD_GRAYSCALE) # Known image
test_image = cv2.imread("tutorialspoint.jpg", cv2.IMREAD_GRAYSCALE) # Image to recognize
# Check if images are loaded
if reference_image is None or test_image is None:
print("Error: Could not load images. Check the file paths.")
exit()
# Initialize ORB detector
orb = cv2.ORB_create()
# Detect keypoints and compute descriptors
keypoints1, descriptors1 = orb.detectAndCompute(reference_image, None)
keypoints2, descriptors2 = orb.detectAndCompute(test_image, None)
# Create a BFMatcher (Brute Force Matcher) and match descriptors
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(descriptors1, descriptors2)
# Sort matches based on distance (lower is better)
matches = sorted(matches, key=lambda x: x.distance)
# Draw the top 20 matches
match_image = cv2.drawMatches(reference_image, keypoints1, test_image, keypoints2, matches[:20], None, flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
# Show the matched features
cv2.imshow("Matched Features", match_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# Print similarity score
print(f"Number of good matches: {len(matches)}")
Input Image:

Following is the output of the above code −
Number of good matches: 419
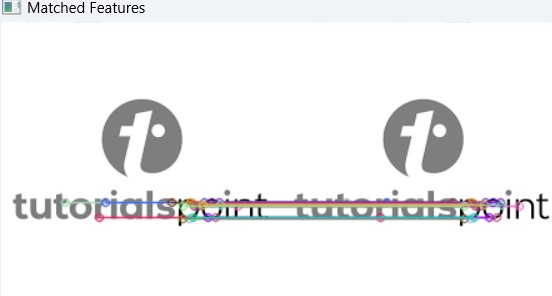
Image Matching
Image Matching is a one of the crucial task in computer vision that involves comparing two images to determine similarities or differences. This process is widely used in object recognition, augmented reality, image retrieval and 3D reconstruction. Image matching algorithms extract the key features from images and use various techniques to establish correspondences between them.
Key Components of Image Matching
Following are the key components of Image Matching in Computer Vision −
- Feature Detection identifies key points in an image such as edges, corners or unique textures to extract useful information.
- Feature Description is used to represents detected features in a format that allows efficient matching between different images.
- Feature Matching compares feature descriptors between two images to find correspondences by using methods such as brute-force matching, FLANN or homography.
- Geometric Verification ensures that the matched features align correctly using techniques such as RANSAC to remove incorrect matches.
Steps in Image Matching
To perform Image Matching we need to follow the below mentioned steps −
Image Acquisition and Preprocessing
Before performing image matching the images must be preprocessed to enhance quality by performing below steps −
- Resizing & Normalization method standardizes the image dimensions and pixel values.
- Noise Reduction removes unwanted distortions using filters such as Gaussian Blur.
- Color Space Conversion is used to convert RGB images to grayscale to reduce computational complexity.
Feature Detection and Extraction
Feature detection identifies key attributes of an image such as edges, shapes and textures. Common methods such as Edge Detection, Histogram of Oriented Gradients (HOG) and Keypoint Detection.
Feature Matching
Once features are extracted then they are matched between two images using various algorithms as below −
- Brute-Force Matcher compares each feature descriptor in one image with all features in another.
- FLANN (Fast Library for Approximate Nearest Neighbors) uses optimized search algorithms for large datasets.
- RANSAC (Random Sample Consensus) filters incorrect matches by estimating a transformation model.
Example of Image Matching
In this example, we use the OpenCV library to match features between two images −
import cv2
import numpy as np
# Load reference and test images in grayscale
reference_image = cv2.imread("tutorialspoint.jpg", cv2.IMREAD_GRAYSCALE) # Known image
test_image = cv2.imread("tutorialspoint.jpg", cv2.IMREAD_GRAYSCALE) # Image to compare
# Check if images are loaded
if reference_image is None or test_image is None:
print("Error: Could not load images. Check the file paths.")
exit()
# Initialize ORB detector
orb = cv2.ORB_create()
# Detect keypoints and compute descriptors
keypoints1, descriptors1 = orb.detectAndCompute(reference_image, None)
keypoints2, descriptors2 = orb.detectAndCompute(test_image, None)
# Create a BFMatcher (Brute Force Matcher) and match descriptors
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(descriptors1, descriptors2)
# Sort matches based on distance (lower is better)
matches = sorted(matches, key=lambda x: x.distance)
# Draw the top 20 matches
match_image = cv2.drawMatches(reference_image, keypoints1, test_image, keypoints2, matches[:20], None, flags=cv2.DrawMatchesFlags_NOT_DRAW_SINGLE_POINTS)
# Show the matched features
cv2.imshow("Matched Features", match_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# Print similarity score
print(f"Number of good matches: {len(matches)}")
Following is the output of the above code −
Number of good matches: 419

