- ChatGPT - Home
- ChatGPT - Fundamentals
- ChatGPT - Getting Started
- ChatGPT - How It Works
- ChatGPT - Prompts
- ChatGPT - Competitors
- ChatGPT - For Content Creation
- ChatGPT - For Marketing
- ChatGPT - For Job Seekers
- ChatGPT - For Code Writing
- ChatGPT - For SEO
- ChatGPT - For Business
- ChatGPT - Machine Learning
- ChatGPT - Generative AI
- ChatGPT - Build a Chatbot
- ChatGPT - Plugin
- ChatGPT - GPT-4o (Omni)
- ChatGPT in Excel
- ChatGPT for Test Automation
- ChatGPT on Android
- Make Money with ChatGPT
- ChatGPT for UI/UX Designers
- ChatGPT for Web Developers
- ChatGPT for Data Scientists
- ChatGPT for Bloggers
- ChatGPT for Personal Finance Management
- Automate Customer Support with ChatGPT
- Create Content Calendars with ChatGPT
- Plan Events and Trips with ChatGPT
- Draft Legal Documents with ChatGPT
- Improve Your Coding Skills with ChatGPT
- New Language with ChatGPT
- Optimize ChatGPT Responses for Better Accuracy
- ChatGPT Useful Resources
- ChatGPT - Quick Guide
- ChatGPT - Useful Resources
- ChatGPT - Discussion
ChatGPT Machine Learning
What is the foundation model that empowers ChatGPTs remarkable capabilities?
ChatGPT's functionality is built on the foundations of machine learning with key contributions from its types-supervised, unsupervised, and reinforcement learning. In this chapter, we will see how machine learning contributes to ChatGPTs capabilities.
What is Machine Learning?
Machine learning is that dynamic field of Artificial Intelligence (AI) with the help of which computer system extract patterns from raw data through algorithms or models. These algorithms enable computers to learn from experience autonomously and make predictions or decisions without being explicitly programmed.
Now, lets understand the types of machine learning and their contribution in shaping ChatGPTs capabilities.
Supervised Learning
Supervised learning is a category of machine learning where an algorithm or model is trained using a labeled dataset. In this approach, the algorithm is provided with input-output pairs, where each input is associated with a corresponding output or label. The goal of supervised learning is for the model to learn the mapping or relationship between inputs and outputs so that it can make accurate predictions or classifications on new, unseen data.
ChatGPT uses supervised learning to initially train its language model. During this first phase, the language model is trained using labeled data containing pairs of input and output examples. In the context of ChatGPT, the input comprises a portion of text, and the corresponding output is the continuation or response to that text.
This annotated data helps the model learn the associations between different words, phrases, and their contextual relevance. ChatGPT, through exposure to diverse examples, utilizes this information to predict the most likely next word or sequence of words based on the given input. Thats how supervised learning becomes the foundation for ChatGPTs ability to understand and generate human-like text.
Unsupervised Learning
Unsupervised learning is a machine learning approach where algorithms or models analyze and derive insights from the data autonomously, without the guidance of labeled examples. In simple words, the goal of this approach is to find the inherent patterns, structures, or relationships within unlabeled data.
Supervised learning provides a solid foundation for ChatGPT, but the true magic of ChatGPT lies in the ability to creatively generate coherent and contextually relevant answers or responses. This is where the role of unsupervised learning comes into effect.
With the help of extensive pre-training on a diverse range of internet text, ChatGPT develops a deep understanding of facts, reasoning abilities, and language patterns. Thats how unsupervised learning unleashes ChatGPTs creativity and enables it to generate meaningful responses to a wide array of user inputs.
Reinforcement Learning
Compared to supervised learning, reinforcement learning (RL) is a type of machine learning paradigm where an agent learns to make decisions by interacting with an environment. The agent takes actions in the environment, receives feedback in the form of rewards or punishments, and uses this feedback to improve its decision-making strategy over time.
Reinforcement learning acts as a navigational compass that guides ChatGPT through dynamic and evolving conversations. After the initial supervised and unsupervised learning phases, the model undergoes reinforcement learning to fine-tune its responses based on user feedback.
Large language models (LLMs) are like super-smart tools that derive knowledge from vast amounts of text. Now, imagine making these tools even smarter by using a technique called reinforcement learning. It's like teaching them to turn their knowledge into useful actions. This intellectual combination is the magic behind something called Reinforcement Learning with Human Feedback (RLHF), making these language models even better at understanding and responding to us.
Reinforcement Learning with Human Feedback (RLHF)
In 2017, OpenAI published a research paper titled Deep reinforcement learning from human preferences in which it unveiled Reinforcement Learning with Human Feedback (RLHF) for the first time. Sometimes we need to operate in situations where we use reinforcement learning, but the task at hand is tough to explain. In such scenarios human feedback becomes important and can make a huge impact.
RLHF works by involving small increments of human feedback to refine the agents learning process. Lets understand its overall training process, which is basically a three-step feedback cycle, with the help of this diagram −
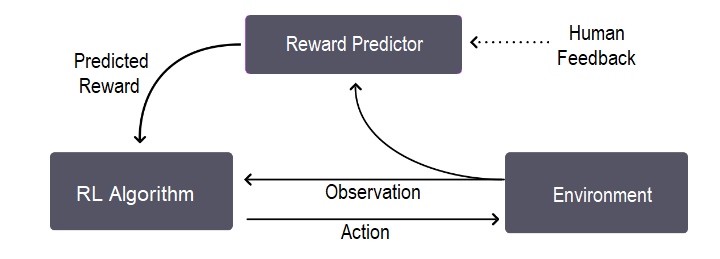
As we can see in the image, the feedback cycle is between the agents understanding of the goal, human feedback, and the reinforcement learning training.
RLHF, initially used in areas like robotics, proves itself to provide a more controlled user experience. Thats why major companies like OpenAI, Meta, Google, Amazon Web Services, IBM, DeepMind, Anthropic, and more have added RLHF to their Large Language Models (LLMs). In fact, RLHF has become a key building block of the most popular LLM-ChatGPT.
ChatGPT and RLHF
In this section, we will explain how ChatGPT used RLHF to align to the human feedback.
OpenAI utilized reinforcement learning with human feedback in a loop, known as RLHF, to train their InstructGPT models. Prior to this, the OpenAI API was driven by GPT-3 language model which tends to produce outputs that may be untruthful and toxic because they are not aligned with their users.
On the other hand, InstructGPT models are much better than GPT-3 model because they −
Make up facts less often and
Show small decrease in generation of toxic outputs.
Steps to Fine-tune ChatGPT with RLHF
For ChatGPT, OpenAI adopted a similar approach to InstructGPT models, with a minor difference in the setup for data collection.
Step 1: The SFT (Supervised Fine-Tuning) Model
The first step mainly involves data collection to train a supervised policy model, known as the SFT model. For data collection, a set of prompts is chosen, and a group of human labelers is then asked to demonstrate the desired output.
Now, instead of fine-tuning the original GPT-3 model, the developers of a versatile chatbot like ChatGPT decided to use a pretrained model from the GPT-3.5 series. In other words, the developers opted to fine-tune on top of a "code model" instead of purely text-based model.
A major issue with the SFT model derived from this step is its tendency to experience misalignment, leading to an output that lacks user attentiveness.
Step 2: The Reward Model (RM)
The primary objective of this step is to acquire an objective function directly from the data. This objective function assigns scores to the SFT model outputs, reflecting their desirability for humans in proportion.
Lets see how it works −
First, a list of prompts and SFT model outputs are sampled.
A labeler then ranks these outputs from best to worst. The dataset now becomes 10 times bigger than the baseline dataset used in the first step for SFT model.
The new data set is now used to train our reward model (RM).
Step 3: Fine-tuning the SFT Policy Using PPO (Proximal Policy Optimization)
In this step, a specific algorithm of reinforcement learning called Proximal Policy Optimization (PPO) is applied to fine tune the SFT model allowing it to optimize the RM. The output of this step is a fine tune model called the PPO model. Lets understand how it works −
First, a new prompt is selected from the dataset.
Now, the PPO model is initialized to fine-tune the SFT model.
This policy now generates an output and then the RM calculates a reward from that output.
This reward is then used to update the policy using PPO.
Conclusion
In this chapter, we explained how machine learning empowers ChatGPTs remarkable capabilities. We also understood how the machine learning paradigms (Supervised, Unsupervised, and Reinforcement learning) contribute to shaping ChatGPTs capabilities.
With the help of RLHF (Reinforcement Learning with Human Feedback), we explored the importance of human feedback and its huge impact on the performance of general-purpose chatbots like ChatGPT.
