- Cassandra - Home
- Cassandra - Introduction
- Cassandra - Architecture
- Cassandra - Data Model
- Cassandra - Installation
- Cassandra - Referenced Api
- Cassandra - Cqlsh
- Cassandra - Shell Commands
- Cassandra Table Operations
- Cassandra - Create Table
- Cassandra - Alter Table
- Cassandra - Drop Table
- Cassandra - Truncate Table
- Cassandra - Create Index
- Cassandra - Drop Index
- Cassandra - Batch
- Cassandra CURD Operations
- Cassandra - Create Data
- Cassandra - Update Data
- Cassandra - Read Data
- Cassandra - Delete Data
- Cassandra CQL Types
- Cassandra - CQL Datatypes
- Cassandra - CQL Collections
- CQL User Defined Datatypes
- Cassandra Useful Resources
- Cassandra - Quick Guide
- Cassandra - Useful Resources
- Cassandra - Discussion
Cassandra - Architecture & Data Model
The design goal of Cassandra is to handle big data workloads across multiple nodes without single point of failure. Cassandra has peer-to-peer distributed system across nodes, and data is distributed among all nodes in the cluster. The following figure shows the architecture of Cassandra.

Components of Cassandra
Given below are the key components of Cassandra:
Node - It is the place where data is stored.
Data center - It is a collection of related nodes.
Commit log - The commit log is a crash-recovery mechanism in Cassandra. Every write operation is written to the commit log.
Cluster - A cluster is a component that contains one or more data centers.
Mem-table - A mem-table is a memory-resident data structure. After commit log, the data will be written to the mem-table. Sometimes, for a single-column family, there will be multiple mem-tables.
SSTable - It is a disk file, to which the data is flushed to, from mem-table, when its contents reach a threshold value.
Bloom filter - These are nothing but quick, nondeterministic, algorithms for testing whether an element is a member of a set. It is a special kind of cache. Bloom filters are accessed after every query.
Compaction - The process of freeing up space by merging large accumulated data files is called compaction. During compaction, the data is merged, indexed, sorted, and stored in a new SSTable. Compaction also reduces the number of required seeks.
Users can access Cassandra through nodes using Cassandra Query Language. CQL treats the database (Keyspace) as a container of tables. Programmers use cqlsh: a prompt to work with CQL or separate application language drivers.
Clients approach any of the nodes for their read-write operations. That node (coordinator) plays a proxy between the client and the nodes holding the data.
Write Operations
Every write activity of nodes is captured by the commit logs written in the nodes. Later the data will be captured and stored in the mem-table. Whenever the memtable is full, data will be written into the SStable data file. All writes are automatically partitioned and replicated throughout the cluster. Cassandra periodically consolidates SSTables, discarding unnecessary data.
Read Operations
During read operations, Cassandra gets values from the mem-table, checks bloom filter to find appropriate SSTables, and gets values from SSTables.
Data Mode
Cluster: Cassandra database is distributed over several machines that operate together. The outermost container is known as the Cluster. For failure handling, every node contains a replica; in case of a failure, replica takes charge. Cassandra arranges the nodes in a cluster, in a ring format, and assigns data to them.
Keyspace
Keyspace is the outermost container for data in Cassandra. The basic attributes of Keyspace in Cassandra are:
Replication factor - It is the number of machines in the cluster that will receive copies of the same data.
Replica placement strategy - It is nothing but the strategy to place replicas in the ring. We have strategies such as simple strategy (rackaware strategy), old network topology strategy (rack-aware strategy), and network topology strategy (datacenter-shared strategy).
Column families - Keyspace is a container for a list of one or more column families. A column family, in turn, is a container of a collection of rows. Each row contains ordered columns. Column families represent the structure of your data. Each keyspace has at least one and often many column families.
The syntax of creating a Keyspace is as follows:
CREATE KEYSPACE Keyspace name
WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};
Given below is the schematic view of a Keyspace.
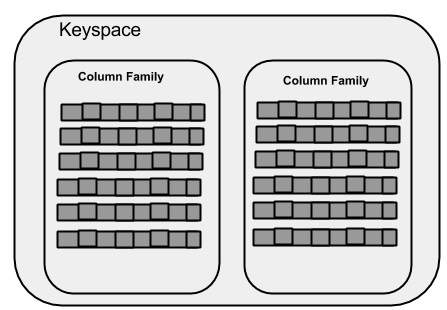
Column Family
A column family is a container for an ordered collection of rows. Each row, in turn, is an ordered collection of columns. The following table lists the points that differentiate a column family from a table of relational databases.
| Relational Table | Cassandra column Family |
|---|---|
| A schema in a relational model is fixed. Once we define certain columns for a table, while inserting data, in every row all the columns must be filled at least with a null value. | In Cassandra, although the column families are defined, the columns are not. You can freely add any column to any column family at any time. |
| Relational tables define only columns and the user fills in the table with values. | In Cassandra, a table contains columns, or can be defined as a super column family. |
A Cassandra column family has the following attributes:
keys_cached - It represents the number of locations to keep cached per SSTable.
rows_cached - It represents the number of rows whose entire contents will be cached in memory.
preload_row_cache - It specifies whether you want to pre-populate the row cache.
Note: Unlike relational tables where a column familys schema is not fixed, Cassandra does not force individual rows to have all the columns.
The following figure shows an example of a Cassandra column family.
.jpg)
Column
A column is the basic data structure of Cassandra with three values, namely key or column name, value, and a time stamp. Given below is the structure of a column.
.jpg)
SuperColumn
A super column is a special column, therefore, it is also a key-value pair. But a super column stores a map of sub-columns.
Generally column families are stored on disk in individual files. Therefore, to optimize performance, it is important to keep columns that you are likely to query together in the same column family, and a super column can be helpful here.Given below is the structure of a super column.
.jpg)
Data Models of Cassandra and RDBMS
Below given is the difference between complete data model of RDBMS and cassandra.
| RDBMS | Cassandra |
|---|---|
| RDBMS deals with structured data. | Cassandra deals with unstructured data. |
| It has a fixed schema. | Cassandra has a flexible schema. |
| In RDBMS, a table is an array of arrays.(ROW x COLUMN) | In Cassandra, a table is a list of nested key-value pairs. (ROW x COLUMN key x COLUMN value) |
| Database is the outermost container that contains data corresponding to an application. | Keyspace is the outermost container that contains data corresponding to an application. |
| Tables are the entities of a database. | Tables or column families are the entity of a keyspace. |
| Row is an individual record in RDBMS. | Row is a unit of replication in Cassandra. |
| Column represents the attributes of a relation. | Column is a unit of storage in Cassandra. |
| RDBMS supports the concepts of foreign keys, joins. | Relationships are represented using collections. |
