- Spark SQL Tutorial
- Spark SQL - Home
- Spark - Introduction
- Spark - RDD
- Spark - Installation
- Spark SQL - Introduction
- Spark SQL - DataFrames
- Spark SQL - Data Sources
- Spark SQL Useful Resources
- Spark SQL - Quick Guide
- Spark SQL - Useful Resources
- Spark SQL - Discussion
Spark SQL - Introduction
Spark introduces a programming module for structured data processing called Spark SQL. It provides a programming abstraction called DataFrame and can act as distributed SQL query engine.
Features of Spark SQL
The following are the features of Spark SQL −
Integrated − Seamlessly mix SQL queries with Spark programs. Spark SQL lets you query structured data as a distributed dataset (RDD) in Spark, with integrated APIs in Python, Scala and Java. This tight integration makes it easy to run SQL queries alongside complex analytic algorithms.
Unified Data Access − Load and query data from a variety of sources. Schema-RDDs provide a single interface for efficiently working with structured data, including Apache Hive tables, parquet files and JSON files.
Hive Compatibility − Run unmodified Hive queries on existing warehouses. Spark SQL reuses the Hive frontend and MetaStore, giving you full compatibility with existing Hive data, queries, and UDFs. Simply install it alongside Hive.
Standard Connectivity − Connect through JDBC or ODBC. Spark SQL includes a server mode with industry standard JDBC and ODBC connectivity.
Scalability − Use the same engine for both interactive and long queries. Spark SQL takes advantage of the RDD model to support mid-query fault tolerance, letting it scale to large jobs too. Do not worry about using a different engine for historical data.
Spark SQL Architecture
The following illustration explains the architecture of Spark SQL −
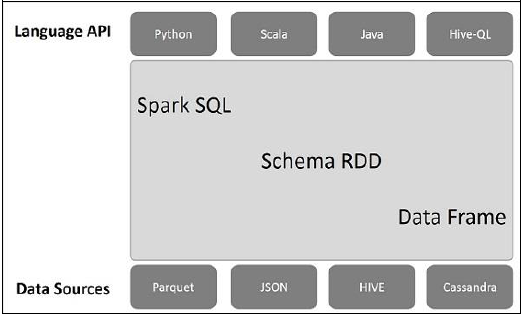
This architecture contains three layers namely, Language API, Schema RDD, and Data Sources.
Language API − Spark is compatible with different languages and Spark SQL. It is also, supported by these languages- API (python, scala, java, HiveQL).
Schema RDD − Spark Core is designed with special data structure called RDD. Generally, Spark SQL works on schemas, tables, and records. Therefore, we can use the Schema RDD as temporary table. We can call this Schema RDD as Data Frame.
Data Sources − Usually the Data source for spark-core is a text file, Avro file, etc. However, the Data Sources for Spark SQL is different. Those are Parquet file, JSON document, HIVE tables, and Cassandra database.
We will discuss more about these in the subsequent chapters.