- spaCy Tutorial
- spaCy - Home
- spaCy - Introduction
- spaCy - Getting Started
- spaCy - Models and Languages
- spaCy - Architecture
- spaCy - Command Line Helpers
- spaCy - Top-level Functions
- spaCy - Visualization Function
- spaCy - Utility Functions
- spaCy - Compatibility Functions
- spaCy - Containers
- Doc Class ContextManager and Property
- spaCy - Container Token Class
- spaCy - Token Properties
- spaCy - Container Span Class
- spaCy - Span Class Properties
- spaCy - Container Lexeme Class
- Training Neural Network Model
- Updating Neural Network Model
- spaCy Useful Resources
- spaCy - Quick Guide
- spaCy - Useful Resources
- spaCy - Discussion
spaCy - Training Neural Network Model
In this chapter, let us learn how to train a neural network model in spaCy.
Here, we will understand how we can update spaCy’s statistical models to customize them for our use case. For Example, to predict a new entity type in online comments. To customize, we first need to train own model.
Steps for Training
Let us understand the steps for training a neural network model in spaCy.
Step1 − Initialization - If you are not taking pre-trained model, then first, we need to initialize the model weights randomly with nlp.begin_training.
Step2 − Prediction - Next, we need to predict some examples with the current weights. It can be done by calling nlp.updates.
Step3 − Compare - Now, the model will check the predictions against true labels.
Step4 − Calculate - After comparing, here, we will decide how to change weights for better prediction next time.
Step5 − Update - At last make a small change in the current weights and pick the next batch of examples. Continue calling nlp.updates for every batch of examples you take.
Let us now understand these steps with the help of below diagram −
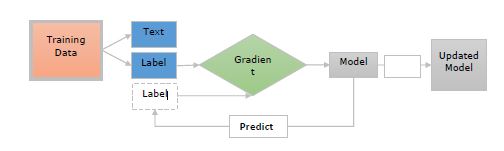
Here −
Training Data − The training data are the examples and their annotations. These are the examples, which we want to update the model with.
Text − It represents the input text, which the model should predict a label for. It should be a sentence, paragraph, or longer document.
Label − The label is actually, what we want from our model to predict. For example, it can be a text category.
Gradient − Gradient is how we should change the weights to reduce the error. It will be computed after comparing the predicted label with true label.
Training the Entity Recognizer
First, the entity recognizer will take a document and predict the phrases as well as their labels.
It means the training data needs to include the following −
Texts.
The entities they contain.
The entity labels.
Each token can only be a part of one entity. Hence, the entities cannot be overlapped.
We should also train it on entities and their surrounding context because, entity recognizer predicts entities in context.
It can be done by showing the model a text and a list of character offsets.
For example, In the code given below, phone is a gadget which starts at character 0 and ends at character 8.
("Phone is coming", {"entities": [(0, 8, "GADGET")]})
Here, the model should also learn the words other than entities.
Consider another example for training the entity recognizer, which is given below −
("I need a new phone! Any suggestions?", {"entities": []})
The main goal should be to teach our entity recognizer model, to recognize new entities in similar contexts even if, they were not in the training data.
spaCy’s Training Loop
Some libraries provide us the methods that takes care of model training but, on the other hand, spaCy provides us full control over the training loop.
Training loop may be defined as a series of steps which is performed to update as well as to train a model.
Steps for Training Loop
Let us see the steps for training loop, which are as follows −
Step 1 − Loop - The first step is to loop, which we usually need to perform several times, so that the model can learn from it. For example, if you want to train your model for 20 iterations, you need to loop 20 times.
Step 2 − Shuffle - Second step is to shuffle the training data. We need to shuffle the data randomly for each iteration. It helps us to prevent the model from getting stuck in a suboptimal solution.
Step 3 − Divide – Later on divide the data into batches. Here, we will divide the training data into mini batches. It helps in increasing the readability of the gradient estimates.
Step 4 − Update - Next step is to update the model for each step. Now, we need to update the model and start the loop again, until we reach the last iteration.
Step 5 − Save - At last, we can save this trained model and use it in spaCy.
Example
Following is an example of spaCy’s Training loop −
DATA = [
("How to order the Phone X", {"entities": [(20, 28, "GADGET")]})
]
# Step1: Loop for 10 iterations
for i in range(10):
# Step2: Shuffling the training data
random.shuffle(DATA)
# Step3: Creating batches and iterating over them
for batch in spacy.util.minibatch(DATA):
# Step4: Splitting the batch in texts and annotations
texts = [text for text, annotation in batch]
annotations = [annotation for text, annotation in batch]
# Step5: Updating the model
nlp.update(texts, annotations)
# Step6: Saving the model
nlp.to_disk(path_to_model)