- Prolog Tutorial
- Prolog - Home
- Prolog - Introduction
- Prolog - Environment Setup
- Prolog - Hello World
- Prolog - Basics
- Prolog - Relations
- Prolog - Data Objects
- Prolog - Operators
- Loop & Decision Making
- Conjunctions & Disjunctions
- Prolog - Lists
- Recursion and Structures
- Prolog - Backtracking
- Prolog - Different and Not
- Prolog - Inputs and Outputs
- Prolog - Built-In Predicates
- Tree Data Structure (Case Study)
- Prolog - Examples
- Prolog - Basic Programs
- Prolog - Examples of Cuts
- Towers of Hanoi Problem
- Prolog - Linked Lists
- Monkey and Banana Problem
- Prolog Useful Resources
- Prolog - Quick Guide
- Prolog - Useful Resources
- Prolog - Discussion
Prolog - Data Objects
In this chapter, we will learn data objects in Prolog. They can be divided into few different categories as shown below −
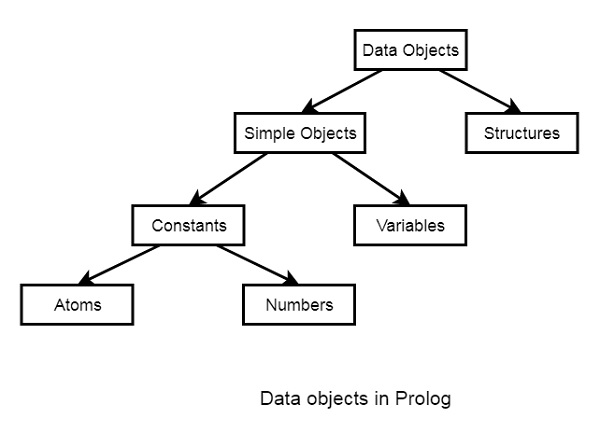
Below are some examples of different kinds of data objects −
Atoms − tom, pat, x100, x_45
Numbers − 100, 1235, 2000.45
Variables − X, Y, Xval, _X
Structures − day(9, jun, 2017), point(10, 25)
Atoms and Variables
In this section, we will discuss the atoms, numbers and the variables of Prolog.
Atoms
Atoms are one variation of constants. They can be any names or objects. There are few rules that should be followed when we are trying to use Atoms as given below −
Strings of letters, digits and the underscore character, ‘_', starting with a lower-case letter. For example −
azahar
b59
b_59
b_59AB
b_x25
antara_sarkar
Strings of special characters
We have to keep in mind that when using atoms of this form, some care is necessary as some strings of special characters already have a predefined meaning; for example ':-'.
<--->
=======>
...
.:.
::=
Strings of characters enclosed in single quotes.
This is useful if we want to have an atom that starts with a capital letter. By enclosing it in quotes, we make it distinguishable from variables −
‘Rubai'
‘Arindam_Chatterjee'
‘Sumit Mitra'
Numbers
Another variation of constants is the Numbers. So integer numbers can be represented as 100, 4, -81, 1202. In Prolog, the normal range of integers is from -16383 to 16383.
Prolog also supports real numbers, but normally the use-case of floating point number is very less in Prolog programs, because Prolog is for symbolic, non-numeric computation. The treatment of real numbers depends on the implementation of Prolog. Example of real numbers are 3.14159, -0.00062, 450.18, etc.
The variables come under the Simple Objects section. Variables can be used in many such cases in our Prolog program, that we have seen earlier. So there are some rules of defining variables in Prolog.
We can define Prolog variables, such that variables are strings of letters, digits and underscore characters. They start with an upper-case letter or an underscore character. Some examples of Variables are −
X
Sum
Memer_name
Student_list
Shoppinglist
_a50
_15
Anonymous Variables in Prolog
Anonymous variables have no names. The anonymous variables in prolog is written by a single underscore character ‘_’. And one important thing is that each individual anonymous variable is treated as different. They are not same.
Now the question is, where should we use these anonymous variables?
Suppose in our knowledge base we have some facts — “jim hates tom”, “pat hates bob”. So if tom wants to find out who hates him, then he can use variables. However, if he wants to check whether there is someone who hates him, we can use anonymous variables. So when we want to use the variable, but do not want to reveal the value of the variable, then we can use anonymous variables.
So let us see its practical implementation −
Knowledge Base (var_anonymous.pl)
hates(jim,tom). hates(pat,bob). hates(dog,fox). hates(peter,tom).
Output
| ?- [var_anonymous]. compiling D:/TP Prolog/Sample_Codes/var_anonymous.pl for byte code... D:/TP Prolog/Sample_Codes/var_anonymous.pl compiled, 3 lines read - 536 bytes written, 16 ms yes | ?- hates(X,tom). X = jim ? ; X = peter yes | ?- hates(_,tom). true ? ; (16 ms) yes | ?- hates(_,pat). no | ?- hates(_,fox). true ? ; no | ?-