- Internet Basics
- Home
- Internet Overview
- Intranet Overview
- Extranet Overview
- Internet reference Models
- Internet Domain Name System
- Internet Services
- Internet Connectivity
- Internet Protocols
- Electronic Mail Basics
- E-Mail Overview
- E-Mail Protocols
- E-Mail Working
- E-Mail Operations
- E-mail Features
- E-Mail Etiquettes
- E-mail Security
- E-mail Providers
- Website Development
- Websites Overview
- Websites Types
- Website Designing
- Websites Development
- Website Publishing
- Website URL Registration
- Website Hosting
- Website Security
- Search Engine Optimization
- Website Monetization
- World Wide Web
- WWW Overview
- Web Pages
- Web Browsers
- Web Servers
- Proxy Servers
- Search Engines
- Internet Collaboration
- Collaboration Overview
- Mailing List
- Usenet Newsgroup
- Online Education
- Social Networking
- Internet Security and Privacy
- Internet Security Overview
- Data Encryption
- Digital Signature
- Firewall Security
- Internet Web Programming
- HTML
- CSS
- JavaScript
- PHP
- Internet Useful Resources
- Internet Quick Guide
- Internet Useful Resources
- Internet Discussion
Search Engines
Introduction
Search Engine refers to a huge database of internet resources such as web pages, newsgroups, programs, images etc. It helps to locate information on World Wide Web.
User can search for any information by passing query in form of keywords or phrase. It then searches for relevant information in its database and return to the user.
Search Engine Components
Generally there are three basic components of a search engine as listed below:
Web Crawler
Database
Search Interfaces
Web crawler
It is also known as spider or bots. It is a software component that traverses the web to gather information.
Database
All the information on the web is stored in database. It consists of huge web resources.
Search Interfaces
This component is an interface between user and the database. It helps the user to search through the database.
Search Engine Working
Web crawler, database and the search interface are the major component of a search engine that actually makes search engine to work. Search engines make use of Boolean expression AND, OR, NOT to restrict and widen the results of a search. Following are the steps that are performed by the search engine:
The search engine looks for the keyword in the index for predefined database instead of going directly to the web to search for the keyword.
It then uses software to search for the information in the database. This software component is known as web crawler.
Once web crawler finds the pages, the search engine then shows the relevant web pages as a result. These retrieved web pages generally include title of page, size of text portion, first several sentences etc.
These search criteria may vary from one search engine to the other. The retrieved information is ranked according to various factors such as frequency of keywords, relevancy of information, links etc.
User can click on any of the search results to open it.
Architecture
The search engine architecture comprises of the three basic layers listed below:
Content collection and refinement.
Search core
User and application interfaces
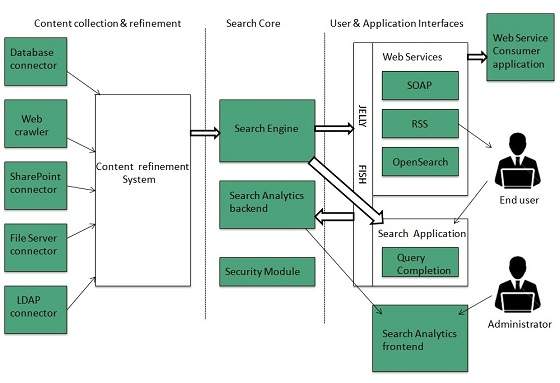
Search Engine Processing
Indexing Process
Indexing process comprises of the following three tasks:
Text acquisition
Text transformation
Index creation
Text acquisition
It identifies and stores documents for indexing.
Text Transformation
It transforms document into index terms or features.
Index Creation
It takes index terms created by text transformations and create data structures to suport fast searching.
Query Process
Query process comprises of the following three tasks:
User interaction
Ranking
Evaluation
User interaction
It supporst creation and refinement of user query and displays the results.
Ranking
It uses query and indexes to create ranked list of documents.
Evaluation
It monitors and measures the effectiveness and efficiency. It is done offline.
Examples
Following are the several search engines available today:
| Search Engine | Description |
|---|---|
| It was originally called BackRub. It is the most popular search engine globally. | |
| Bing | It was launched in 2009 by Microsoft. It is the latest web-based search engine that also delivers Yahoo’s results. |
| Ask | It was launched in 1996 and was originally known as Ask Jeeves. It includes support for match, dictionary, and conversation question. |
| AltaVista | It was launched by Digital Equipment Corporation in 1995. Since 2003, it is powered by Yahoo technology. |
| AOL.Search | It is powered by Google. |
| LYCOS | It is top 5 internet portal and 13th largest online property according to Media Matrix. |
| Alexa | It is subsidiary of Amazon and used for providing website traffic information. |