
- Compiler Design Tutorial
- Compiler Design - Home
- Compiler Design - Overview
- Compiler Design - Architecture
- Compiler Design - Phases of Compiler
- Compiler Design - Lexical Analysis
- Compiler - Regular Expressions
- Compiler Design - Finite Automata
- Compiler Design - Syntax Analysis
- Compiler Design - Types of Parsing
- Compiler Design - Top-Down Parser
- Compiler Design - Bottom-Up Parser
- Compiler Design - Error Recovery
- Compiler Design - Semantic Analysis
- Compiler - Run-time Environment
- Compiler Design - Symbol Table
- Compiler - Intermediate Code
- Compiler Design - Code Generation
- Compiler Design - Code Optimization
- Compiler Design Useful Resources
- Compiler Design - Quick Guide
- Compiler Design - Useful Resources
Compiler Design - Semantic Analysis
We have learnt how a parser constructs parse trees in the syntax analysis phase. The plain parse-tree constructed in that phase is generally of no use for a compiler, as it does not carry any information of how to evaluate the tree. The productions of context-free grammar, which makes the rules of the language, do not accommodate how to interpret them.
For example
E → E + T
The above CFG production has no semantic rule associated with it, and it cannot help in making any sense of the production.
Semantics
Semantics of a language provide meaning to its constructs, like tokens and syntax structure. Semantics help interpret symbols, their types, and their relations with each other. Semantic analysis judges whether the syntax structure constructed in the source program derives any meaning or not.
CFG + semantic rules = Syntax Directed Definitions
For example:
int a = “value”;
should not issue an error in lexical and syntax analysis phase, as it is lexically and structurally correct, but it should generate a semantic error as the type of the assignment differs. These rules are set by the grammar of the language and evaluated in semantic analysis. The following tasks should be performed in semantic analysis:
- Scope resolution
- Type checking
- Array-bound checking
Semantic Errors
We have mentioned some of the semantics errors that the semantic analyzer is expected to recognize:
- Type mismatch
- Undeclared variable
- Reserved identifier misuse.
- Multiple declaration of variable in a scope.
- Accessing an out of scope variable.
- Actual and formal parameter mismatch.
Attribute Grammar
Attribute grammar is a special form of context-free grammar where some additional information (attributes) are appended to one or more of its non-terminals in order to provide context-sensitive information. Each attribute has well-defined domain of values, such as integer, float, character, string, and expressions.
Attribute grammar is a medium to provide semantics to the context-free grammar and it can help specify the syntax and semantics of a programming language. Attribute grammar (when viewed as a parse-tree) can pass values or information among the nodes of a tree.
Example:
E → E + T { E.value = E.value + T.value }
The right part of the CFG contains the semantic rules that specify how the grammar should be interpreted. Here, the values of non-terminals E and T are added together and the result is copied to the non-terminal E.
Semantic attributes may be assigned to their values from their domain at the time of parsing and evaluated at the time of assignment or conditions. Based on the way the attributes get their values, they can be broadly divided into two categories : synthesized attributes and inherited attributes.
Synthesized attributes
These attributes get values from the attribute values of their child nodes. To illustrate, assume the following production:
S → ABC
If S is taking values from its child nodes (A,B,C), then it is said to be a synthesized attribute, as the values of ABC are synthesized to S.
As in our previous example (E → E + T), the parent node E gets its value from its child node. Synthesized attributes never take values from their parent nodes or any sibling nodes.
Inherited attributes
In contrast to synthesized attributes, inherited attributes can take values from parent and/or siblings. As in the following production,
S → ABC
A can get values from S, B and C. B can take values from S, A, and C. Likewise, C can take values from S, A, and B.
Expansion : When a non-terminal is expanded to terminals as per a grammatical rule
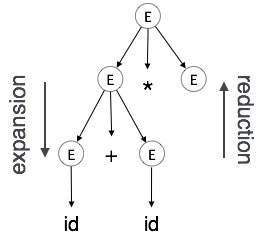
Reduction : When a terminal is reduced to its corresponding non-terminal according to grammar rules. Syntax trees are parsed top-down and left to right. Whenever reduction occurs, we apply its corresponding semantic rules (actions).
Semantic analysis uses Syntax Directed Translations to perform the above tasks.
Semantic analyzer receives AST (Abstract Syntax Tree) from its previous stage (syntax analysis).
Semantic analyzer attaches attribute information with AST, which are called Attributed AST.
Attributes are two tuple value, <attribute name, attribute value>
For example:
int value = 5; <type, “integer”> <presentvalue, “5”>
For every production, we attach a semantic rule.
S-attributed SDT
If an SDT uses only synthesized attributes, it is called as S-attributed SDT. These attributes are evaluated using S-attributed SDTs that have their semantic actions written after the production (right hand side).
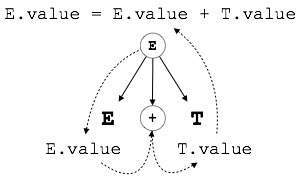
As depicted above, attributes in S-attributed SDTs are evaluated in bottom-up parsing, as the values of the parent nodes depend upon the values of the child nodes.
L-attributed SDT
This form of SDT uses both synthesized and inherited attributes with restriction of not taking values from right siblings.
In L-attributed SDTs, a non-terminal can get values from its parent, child, and sibling nodes. As in the following production
S → ABC
S can take values from A, B, and C (synthesized). A can take values from S only. B can take values from S and A. C can get values from S, A, and B. No non-terminal can get values from the sibling to its right.
Attributes in L-attributed SDTs are evaluated by depth-first and left-to-right parsing manner.
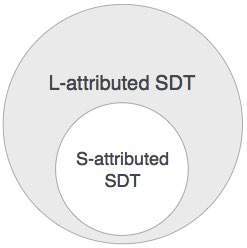
We may conclude that if a definition is S-attributed, then it is also L-attributed as L-attributed definition encloses S-attributed definitions.