- Beautiful Soup Tutorial
- Beautiful Soup - Home
- Beautiful Soup - Overview
- Beautiful Soup - Web Scraping
- Beautiful Soup - Installation
- Beautiful Soup - Souping the Page
- Beautiful Soup - Kinds of objects
- Beautiful Soup - Inspect Data Source
- Beautiful Soup - Scrape HTML Content
- Beautiful Soup - Navigating by Tags
- Beautiful Soup - Find Elements by ID
- Beautiful Soup - Find Elements by Class
- Beautiful Soup - Find Elements by Attribute
- Beautiful Soup - Searching the Tree
- Beautiful Soup - Modifying the Tree
- Beautiful Soup - Parsing a Section of a Document
- Beautiful Soup - Find all Children of an Element
- Beautiful Soup - Find Element using CSS Selectors
- Beautiful Soup - Find all Comments
- Beautiful Soup - Scraping List from HTML
- Beautiful Soup - Scraping Paragraphs from HTML
- BeautifulSoup - Scraping Link from HTML
- Beautiful Soup - Get all HTML Tags
- Beautiful Soup - Get Text Inside Tag
- Beautiful Soup - Find all Headings
- Beautiful Soup - Extract Title Tag
- Beautiful Soup - Extract Email IDs
- Beautiful Soup - Scrape Nested Tags
- Beautiful Soup - Parsing Tables
- Beautiful Soup - Selecting nth Child
- Beautiful Soup - Search by text inside a Tag
- Beautiful Soup - Remove HTML Tags
- Beautiful Soup - Remove all Styles
- Beautiful Soup - Remove all Scripts
- Beautiful Soup - Remove Empty Tags
- Beautiful Soup - Remove Child Elements
- Beautiful Soup - find vs find_all
- Beautiful Soup - Specifying the Parser
- Beautiful Soup - Comparing Objects
- Beautiful Soup - Copying Objects
- Beautiful Soup - Get Tag Position
- Beautiful Soup - Encoding
- Beautiful Soup - Output Formatting
- Beautiful Soup - Pretty Printing
- Beautiful Soup - NavigableString Class
- Beautiful Soup - Convert Object to String
- Beautiful Soup - Convert HTML to Text
- Beautiful Soup - Parsing XML
- Beautiful Soup - Error Handling
- Beautiful Soup - Trouble Shooting
- Beautiful Soup - Porting Old Code
- Beautiful Soup - Functions Reference
- Beautiful Soup - contents Property
- Beautiful Soup - children Property
- Beautiful Soup - string Property
- Beautiful Soup - strings Property
- Beautiful Soup - stripped_strings Property
- Beautiful Soup - descendants Property
- Beautiful Soup - parent Property
- Beautiful Soup - parents Property
- Beautiful Soup - next_sibling Property
- Beautiful Soup - previous_sibling Property
- Beautiful Soup - next_siblings Property
- Beautiful Soup - previous_siblings Property
- Beautiful Soup - next_element Property
- Beautiful Soup - previous_element Property
- Beautiful Soup - next_elements Property
- Beautiful Soup - previous_elements Property
- Beautiful Soup - find Method
- Beautiful Soup - find_all Method
- Beautiful Soup - find_parents Method
- Beautiful Soup - find_parent Method
- Beautiful Soup - find_next_siblings Method
- Beautiful Soup - find_next_sibling Method
- Beautiful Soup - find_previous_siblings Method
- Beautiful Soup - find_previous_sibling Method
- Beautiful Soup - find_all_next Method
- Beautiful Soup - find_next Method
- Beautiful Soup - find_all_previous Method
- Beautiful Soup - find_previous Method
- Beautiful Soup - select Method
- Beautiful Soup - append Method
- Beautiful Soup - extend Method
- Beautiful Soup - NavigableString Method
- Beautiful Soup - new_tag Method
- Beautiful Soup - insert Method
- Beautiful Soup - insert_before Method
- Beautiful Soup - insert_after Method
- Beautiful Soup - clear Method
- Beautiful Soup - extract Method
- Beautiful Soup - decompose Method
- Beautiful Soup - replace_with Method
- Beautiful Soup - wrap Method
- Beautiful Soup - unwrap Method
- Beautiful Soup - smooth Method
- Beautiful Soup - prettify Method
- Beautiful Soup - encode Method
- Beautiful Soup - decode Method
- Beautiful Soup - get_text Method
- Beautiful Soup - diagnose Method
- Beautiful Soup Useful Resources
- Beautiful Soup - Quick Guide
- Beautiful Soup - Useful Resources
- Beautiful Soup - Discussion
Beautiful Soup - Overview
In today's world, we have tons of unstructured data/information (mostly web data) available freely. Sometimes the freely available data is easy to read and sometimes not. No matter how your data is available, web scraping is very useful tool to transform unstructured data into structured data that is easier to read and analyze. In other words, web scraping is a way to collect, organize and analyze this enormous amount of data. So let us first understand what is web-scraping.
Introduction to Beautiful Soup
The Beautiful Soup is a python library which is named after a Lewis Carroll poem of the same name in "Alice's Adventures in the Wonderland". Beautiful Soup is a python package and as the name suggests, parses the unwanted data and helps to organize and format the messy web data by fixing bad HTML and present to us in an easily-traversable XML structures.
In short, Beautiful Soup is a python package which allows us to pull data out of HTML and XML documents.
HTML tree Structure
Before we look into the functionality provided by Beautiful Soup, let us first understand the HTML tree structure.
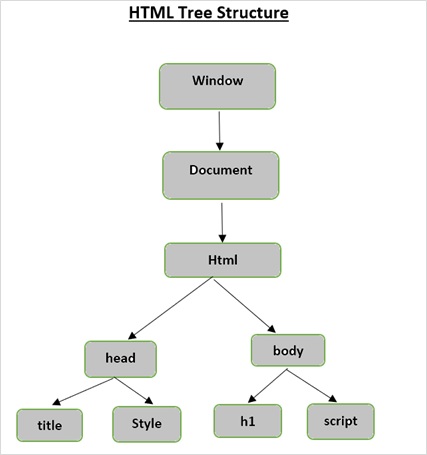
The root element in the document tree is the html, which can have parents, children and siblings and this determines by its position in the tree structure. To move among HTML elements, attributes and text, you have to move among nodes in your tree structure.
Let us suppose the webpage is as shown below −

Which translates to an html document as follows −
<html>
<head>
<title>TutorialsPoint</title>
</head>
<body>
<h1>Tutorialspoint Online Library</h1>
<p><b>It's all Free</b></p>
</body>
</html>
Which simply means, for above html document, we have a html tree structure as follows −