- Apache Flume Tutorial
- Apache Flume - Home
- Apache Flume - Introduction
- Data Transfer in Hadoop
- Apache Flume - Architecture
- Apache Flume - Data Flow
- Apache Flume - Environment
- Apache Flume - configuration
- Apache Flume - Fetching Twitter Data
- Sequence Generator Source
- Apache Flume - NetCat Source
- Apache Flume Resources
- Apache Flume - Quick Guide
- Apache Flume - Useful Resources
- Apache Flume - Discussion
Apache Flume - Introduction
What is Flume?
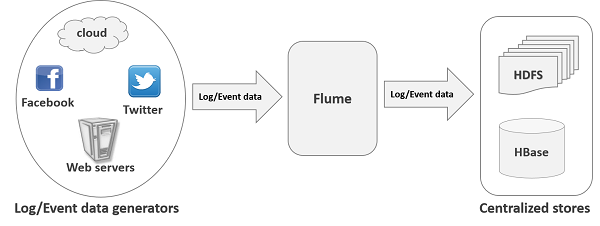
Apache Flume is a tool/service/data ingestion mechanism for collecting aggregating and transporting large amounts of streaming data such as log files, events (etc...) from various sources to a centralized data store.
Flume is a highly reliable, distributed, and configurable tool. It is principally designed to copy streaming data (log data) from various web servers to HDFS.
Applications of Flume
Assume an e-commerce web application wants to analyze the customer behavior from a particular region. To do so, they would need to move the available log data in to Hadoop for analysis. Here, Apache Flume comes to our rescue.
Flume is used to move the log data generated by application servers into HDFS at a higher speed.
Advantages of Flume
Here are the advantages of using Flume −
Using Apache Flume we can store the data in to any of the centralized stores (HBase, HDFS).
When the rate of incoming data exceeds the rate at which data can be written to the destination, Flume acts as a mediator between data producers and the centralized stores and provides a steady flow of data between them.
Flume provides the feature of contextual routing.
The transactions in Flume are channel-based where two transactions (one sender and one receiver) are maintained for each message. It guarantees reliable message delivery.
Flume is reliable, fault tolerant, scalable, manageable, and customizable.
Features of Flume
Some of the notable features of Flume are as follows −
Flume ingests log data from multiple web servers into a centralized store (HDFS, HBase) efficiently.
Using Flume, we can get the data from multiple servers immediately into Hadoop.
Along with the log files, Flume is also used to import huge volumes of event data produced by social networking sites like Facebook and Twitter, and e-commerce websites like Amazon and Flipkart.
Flume supports a large set of sources and destinations types.
Flume supports multi-hop flows, fan-in fan-out flows, contextual routing, etc.
Flume can be scaled horizontally.